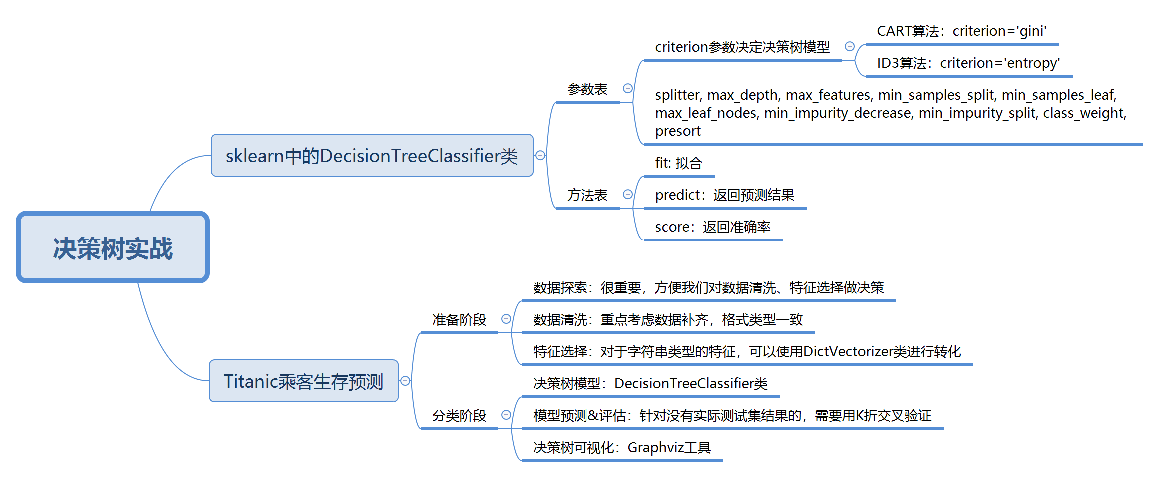
决策树实战
决策树算法是经常使用的数据挖掘算法,这是因为决策树就像一个人脑中的决策模型一样,呈现出来非常直观
基于决策树还诞生了很多数据挖掘算法,比如随机森林(Random forest)
决策树分类的应用场景非常广泛,在各行各业都有应用
比如在金融行业可以用决策树做贷款风险评估,医疗行业可以用决策树生成辅助诊断,电商行业可以用决策树对销售额进行预测等
在了解决策树的原理后,我们用Python的sklearn库来解决一些实际的问题
sklearn
| 参数 | 描述 |
|---|---|
| criterion | 在基于特征划分数据集合时,选择特征的标准。默认是gini,也可以是entropy |
| splitter | 在构造树时,选择属性特征的原则,可以是best或random。默认是best,best在所有特征中选择最好的,random在部分特征中选择最好的 |
| max_depth | 决策树的最大深度,我们可以控制决策树深度来防止过拟合 |
| max_features | 在划分数据集时考虑的最多的特征值数量。为int或float。int表示每次split时的最大特征数。float表示百分数,即特征数=max_features*n_features |
| min_samples_split | 当节点的样本数小于min_samples_split时,不再继续分裂。默认为2 |
| min_samples_leaf | 叶子节点需要的最小样本数。如果某叶子节点数小于这个阈值,则会和兄弟节点一起被减枝。为int或float。int表示最小样本数。float表示一个百分比,为min_samples_leaf乘以样本数量并向上取整 |
| max_leaf_nodes | 最大叶子节点数。int类型,默认为None。默认不设置最大叶子节点数,特征多时,可以通过设置最大叶子节点数防止过拟合 |
| min_impurity_decrease | 节点划分最小不纯度。float类型,默认为0。节点的不纯度必须大于这个阈值,否则该节点不再生成子节点。通过设置,可以限制决策树的增长 |
| min_impurity_split | 信息增益的阈值。信息增益必须大于这个阈值,否则不分裂 |
| class_weight | 类别权重。默认为None,也可以是dict或balanced。dict类型:指定样本各类别的权重,权重大的类别在决策树构造的时候会进行偏倚。balanced:算法自己计算权重,样本量少的类别所对应的样本权重会更高 |
| presort | bool类型,默认是false,表示在拟合前,是否对数据进行排序来加快树的构建。当数据集较小时,使用presort=true会加快分类构造速度。当数据集庞大时,presort=true会导致整个分类非常缓慢 |
一般只需要设置criterion参数来决定使用不同的决策树算法,其他默认就行了
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
在构造决策树分类器后,我们可以使用fit方法让分类器进行拟合,使用predict方法对新数据进行预测,得到预测的分类结果,也可以使用score方法得到分类器的准确率
| 方法名 | 描述 |
|---|---|
| fit(features,labels) | 通过特征矩阵,分类标识,让分类器进行拟合 |
| predict(features) | 返回预测结果 |
| score(features,labels) | 返回准确率 |
泰坦尼克号乘客的生存预测
- train.csv是训练数据集,包含特征信息和存活与否的标签
- test.csv:测试数据集,只包含特征信息
现在我们使用决策树分类对训练集进行训练,针对测试集中的乘客进行生存预测,并告知分类器的准确率
| 字段 | 描述 |
|---|---|
| PassengerId | 乘客编号 |
| Survived | 是否幸存 |
| Pclass | 船票等级 |
| Name | 乘客姓名 |
| Sex | 乘客性别 |
| SibSp | 亲戚数量(兄妹、配偶数) |
| Parch | 亲戚数量(父母、子女数) |
| Ticket | 船票号码 |
| Fare | 船票价格 |
| Cabin | 船舱 |
| Embarked | 登陆港口 |
我们要对训练集中乘客的生存进行预测,这个过程可以划分为两个重要的阶段:
- 准备阶段:我们首先需要对训练集、测试集的数据进行探索,分析数据质量,并对数据进行清洗,然后通过特征选择对数据进行降维,方便后续分类运算
- 分类阶段:首先通过训练集的特征矩阵、分类结果得到决策树分类器,然后将分类器应用于测试集。然后我们对决策树分类器的准确性进行分析,并对决策树模型进行可视化
数据探索
数据探索这部分虽然对分类器没有实质作用,但是不可忽略。我们只有足够了解这些数据的特性,才能帮助我们做数据清洗、特征选择
- 使用info()了解数据表的基本情况:行数、列数、每列的数据类型、数据完整度
- 使用describe()了解数据表的统计情况:总数、平均值、标准差、最小值、最大值等
- 使用describe(include=['O'])查看字符串类型(非数字)的整体情况
- 使用head查看前几行数据(默认是前5行)
- 使用tail查看后几行数据(默认是最后5行)
import pandas as pd
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
# 数据加载
train_data = pd.read_csv('./Titanic_Data/train.csv')
test_data = pd.read_csv('./Titanic_Data/test.csv')
# 数据探索
print(train_data.info())
print('-' * 30)
print(train_data.describe())
print('-' * 30)
print(train_data.describe(include=['O']))
print('-' * 30)
print(train_data.head())
print('-' * 30)
print(train_data.tail())
print('-' * 30)
print(train_data.info())
print('-' * 30)
print(train_data.describe())
print('-' * 30)
print(train_data.describe(include=['O']))
print('-' * 30)
print(train_data.head())
print('-' * 30)
print(train_data.tail())
数据清洗
通过数据探索,我们发现Age、Cabin、Embarked这三个字段的数据有所缺失
其中Age为年龄字段,是数值型,我们可以通过平均值进行补齐
Cabin为船舱,有大量的缺失值。在训练集和测试集中的缺失率分别为77%和78%,无法补齐
Embarked为登陆港口,有少量的缺失值,我们可以把缺失值补齐
# 使用平均年龄来填充年龄中的nan值
train_data['Age'].fillna(train_data['Age'].mean(), inplace=True)
test_data['Age'].fillna(test_data['Age'].mean(),inplace=True)
# 首先观察下Embarked字段的取值
print(train_data['Embarked'].value_counts())
# 使用登录最多的港口来填充登录港口的nan值
train_data['Embarked'].fillna('S', inplace=True)
test_data['Embarked'].fillna('S',inplace=True)
特征选择
特征选择是分类器的关键。特征选择不同,得到的分类器也不同。那么我们该选择哪些特征做生存的预测呢?
通过数据探索我们发现,PassengerId为乘客编号,对分类没有作用,可以放弃
Name为乘客姓名,对分类没有作用,可以放弃
Cabin字段缺失值太多,可以放弃
Ticket字段为船票号码,杂乱无章且无规律,可以放弃
其余的字段包括:Pclass、Sex、Age、SibSp、Parch和Fare,这些属性分别表示了乘客的船票等级、性别、年龄、亲戚数量以及船票价格,可能会和乘客的生存预测分类有关系
具体是什么关系,我们可以交给分类器来处理。因此我们先将Pclass、Sex、Age等这些其余的字段作特征,放到特征向量features里
# 特征选择
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_features = train_data[features]
train_labels = train_data['Survived']
test_features = test_data[features]
特征值里有一些是字符串,这样不方便后续的运算,需要转成数值类型,比如Sex字段,有male和female两种取值。我们可以把它变成Sex=male和Sex=female两个字段,数值用0或1来表示
同理Embarked有S、C、Q三种可能,我们也可以改成Embarked=S、Embarked=C和Embarked=Q三个字段,数值用0或1来表示
那该如何操作呢,我们可以使用sklearn特征选择中的DictVectorizer类,用它将可以处理符号化的对象,将符号转成数字0/1进行表示。具体方法如下:
from sklearn.feature_extraction import DictVectorizer
dvec=DictVectorizer(sparse=False)
train_features=dvec.fit_transform(train_features.to_dict(orient='record'))
# 代码中使用了fit_transform这个函数,它可以将特征向量转化为特征值矩阵
# 然后我们看下dvec在转化后的特征属性是怎样的,即查看dvec的feature_names_属性值
print(dvec.feature_names_)
你可以看到原本是一列的Embarked,变成了“Embarked=C”“Embarked=Q”“Embarked=S”三列。Sex列变成了“Sex=female”“Sex=male”两列
这样train_features特征矩阵就包括10个特征值(列),以及891个样本(行),即891行,10列的特征矩阵
决策树模型
刚才我们已经讲了如何使用sklearn中的决策树模型。现在我们使用ID3算法,即在创建DecisionTreeClassifier时,设置criterion=‘entropy’
然后使用fit进行训练,将特征值矩阵和分类标识结果作为参数传入,得到决策树分类器
from sklearn.tree import DecisionTreeClassifier
# 构造ID3决策树
clf = DecisionTreeClassifier(criterion='entropy')
# 决策树训练
clf.fit(train_features, train_labels)
模型预测和评估
在预测中,我们首先需要得到测试集的特征值矩阵,然后使用训练好的决策树clf进行预测,得到预测结果pred_labels:
test_features=dvec.transform(test_features.to_dict(orient='record'))
# 决策树预测
pred_labels = clf.predict(test_features)
fit_transform()和transform()二者的功能都是对数据进行某种统一处理(如:归一化等)
fit_transform(trainData)对部分训练数据先拟合fit,找到部分训练数据的整体指标,如均值、方差、最大值、最小值等(根据具体转换的目的)
然后对训练数据进行转换transform,从而实现数据的标准化、归一化等
根据对之前部分训练数据进行fit的整体指标,对测试数据集使用同样的均值、方差、最大、最小值等指标进行转换transform(testData),从而保证train、test处理方式相同
在模型评估中,决策树提供了score函数可以直接得到准确率,但是我们并不知道真实的预测结果,所以无法用预测值和真实的预测结果做比较我们只能使用训练集中的数据进行模型评估,可以使用决策树自带的score函数计算下得到的结果:
# 得到决策树准确率
acc_decision_tree = round(clf.score(train_features, train_labels), 6)
print(u'score准确率为 %.4lf' % acc_decision_tree)
你会发现你刚用训练集做训练,再用训练集自身做准确率评估自然会很高。但这样得出的准确率并不能代表决策树分类器的准确率
如果我们使用score函数对训练集的准确率进行统计,正确率会接近于100%(如上结果为98.2%),无法对分类器的在实际环境下做准确率的评估
那么有什么办法,来统计决策树分类器的准确率呢?
这里可以使用K折交叉验证的方式,交叉验证是一种常用的验证分类准确率的方法,原理是拿出大部分样本进行训练,少量的用于分类器的验证
K折交叉验证,就是做K次交叉验证,每次选取K分之一的数据作为验证,其余作为训练。轮流K次,取平均值
K折交叉验证的原理是这样的:
- 将数据集平均分割成K个等份
- 使用1份数据作为测试数据,其余作为训练数据
- 计算测试准确率;使用不同的测试集,重复2、3步骤
在sklearn的model_selection模型选择中提供了cross_val_score函数
cross_val_score函数中的参数cv代表对原始数据划分成多少份,也就是我们的K值,一般建议K值取10
因此我们可以设置CV=10,我们可以对比下score和cross_val_score两种函数的正确率的评估结果
import numpy as np
from sklearn.model_selection import cross_val_score
# 使用K折交叉验证 统计决策树准确率
print(u'cross_val_score准确率为 %.4lf' % np.mean(cross_val_score(clf, train_features, train_labels, cv=10)))
决策树可视化
sklearn的决策树模型对我们来说,还是比较抽象的。我们可以使用Graphviz可视化工具帮我们把决策树呈现出来
安装Graphviz库需要下面的几步:
- 安装graphviz工具 下载
- 将Graphviz添加到环境变量PATH中
- 需要Graphviz库,如果没有可以使用
pip3 install graphviz进行安装
决策树模型使用技巧总结
特征选择是分类模型好坏的关键。选择什么样的特征,以及对应的特征值矩阵,决定了分类模型的好坏。通常情况下,特征值不都是数值类型,可以使用DictVectorizer类进行转化
模型准确率需要考虑是否有测试集的实际结果可以做对比,当测试集没有真实结果可以对比时,需要使用K折交叉验证cross_val_score
Graphviz可视化工具可以很方便地将决策模型呈现出来,帮助你更好理解决策树的构建
完整代码
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 数据加载,测试数据没有结果值,直接把训练集切割下
train_data = pd.read_csv('./train.csv')
# 数据探索
# 一共891行,12列
# 其中Age(年龄)、Cabin(船舱)、Embarked(登陆港口)有缺失数据
print(train_data.info())
print('-' * 30)
# 数量、均值、标准差、百分位数等
print(train_data.describe())
print('-' * 30)
# Name没有重复、Sex只有2类值(其中male较多有577个)...
print(train_data.describe(include=['O']))
print('-' * 30)
print(train_data.head())
print('-' * 30)
print(train_data.tail())
# 数据清洗
# 使用平均年龄来填充年龄中的 nan 值
train_data['Age'].fillna(train_data['Age'].mean(), inplace=True)
# Cabin(船舱)存在大量缺失不做处理
# Embarked(登陆港口)使用频次最高的填充
train_data['Embarked'].fillna(train_data['Embarked'].value_counts().index[0], inplace=True)
# 前700条作为训练数据,后面的作为测试数据
test_data = train_data[700:]
train_data = train_data[0:700]
# 特征选择
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
train_features = train_data[features]
train_labels = train_data['Survived']
test_features = test_data[features]
test_labels = test_data['Survived']
# 将特征值中的一些字符串做数字处理
dvec = DictVectorizer(sparse=False)
train_features = dvec.fit_transform(train_features.to_dict('records'))
# 打印查看新的特征值列名
print(dvec.feature_names_)
test_features = dvec.transform(test_features.to_dict('records'))
# 构造ID3决策树
clf = DecisionTreeClassifier(criterion='entropy')
# 决策树训练
clf.fit(train_features, train_labels)
# 决策树预测
pred_labels = clf.predict(test_features)
# 预测结果与测试集结果作比对
score = accuracy_score(test_labels, pred_labels)
print("泰坦尼克测试集准确率 %.4lf" % score)
print(test_labels.to_list())
print(pred_labels)