PyTorch
参考1:文字版,方便整理(可视化、分布式用到的时候再整理)
参考2:入门视频
参考3:李沐老师的视频(较全面,有具体代码实现,d2l) B站 主页
参考4:李宏毅老师的视频(有14个作业)
论文地址(以残差网络为例):https://arxiv.org/abs/1512.03385,15年12月
CV和NLP的顶会整理如下,相关的论文可以定期关注下
- CV
- CVPR:International Conference on Computer Vision and Pattern Recognition
- ICCV:International Conference on Computer Vision
- ECCV:European Conference on Computer Vision
- NLP
- ACL:Annual Meeting of the Association for Computational Linguistics
- EMNLP:Empirical Methods in Natural Language Processing
- CoNLL:Conference on Computational Natural Language Learning
- COLING:International Conference on Computational Linguistics
安装
CPU版本,测试的时候用CPU版本就可以了(mac系统不支持GPU版本)
# Linux
pip install torch==1.9.0+cpu torchvision==0.10.0+cpu torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
# Mac & Windows
pip install torch torchvision torchaudio
GPU版本,需要安装对应版本的CUDA工具包,查看GPU支持的CUDA 、官网下载
# Linux & Windows
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
检查torch是否支持GPU以及查看torch版本
import torch
print(torch.cuda.is_available())
print(torch.__version__)
在终端中输入"nvidia-smi"命令,会显示出显卡驱动的版本和CUDA的版本
如果显卡驱动的版本过低,与CUDA版本不匹配,那么GPU也不可用,需要根据显卡的型号更新显卡驱动
PyTorch版本同样与CUDA版本有对应关系,我们可以在这个页面查看它们之间的对应关系。如果两者版本不匹配,可以重新安装对应版本的PyTorch,或者升级CUDA工具包
如果使用docker的话,这里有很多的PyTorch的Docker镜像
三步曲
所有深度学习项目都可以简单划分成3步:数据加载、训练与模型评估
训练数据不外乎这三种:图片、文本以及类似二维表那样的结构化数据
我们先以单张图片为例,将图片分别用Pillow与OpenCV读入,然后转换为NumPy的数组
注意:老版本的OpenCV读入后的通道顺序是B、G、R(新版已调整成:R、G、B),以下Pillow中有查看通道颜色值的示例
Pillow
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
# <PIL.PngImagePlugin.PngImageFile image mode=RGBA size=420x180 at 0x114E47E80>
im = Image.open('./test.png')
# (420, 180)
print(im.size)
# Pillow是以二进制形式读入保存的,numpy可以直接接收
# (180, 420, 4) 180行,每行420个RGBA的像素点
im_pillow = np.array(im)
print(im_pillow.shape)
red_background = np.array(im_pillow)
red_background[:, :, 1] = 0
red_background[:, :, 2] = 0
green_background = np.array(im_pillow)
green_background[:, :, 0] = 0
green_background[:, :, 2] = 0
blue_background = np.array(im_pillow)
blue_background[:, :, 0] = 0
blue_background[:, :, 1] = 0
fig, axes = plt.subplots(2, 2)
axes[0, 0].imshow(im_pillow)
axes[0, 0].set_title("origin pic")
# 不要显示坐标轴
axes[0, 0].axis('off')
axes[0, 1].imshow(red_background)
axes[0, 1].set_title("red pic")
axes[0, 1].axis('off')
axes[1, 0].imshow(green_background)
axes[1, 0].set_title("green pic")
axes[1, 0].axis('off')
axes[1, 1].imshow(blue_background)
axes[1, 1].set_title("blue pic")
axes[1, 1].axis('off')
plt.show()
![]()
OpenCV
import cv2
# OpenCV读取后直接是numpy
# (180, 420, 3) 180行,每行420个RGB的像素点(通道的顺序是:B、G、R)
im_cv2 = cv2.imread('./test.png')
print(im_cv2.shape)
模型评估
在模型评估时,我们一般会将模型的输出转换为对应的标签
假设现在我们的问题是将图片分为2个类别,包含logo的图片与不包含logo的图片。模型会输出形状为(2,)的数组
我们把它叫做probs,它存储了两个概率,我们假设索引为0的概率是包含logo图片的概率,另一个是其它图片的概率,它们两个概率的和为1
如果包含logo对应的概率大,则可以推断该图片为包含logo的图片,否则为其他图片
简单的做法就是判断probs[0]是否大于0.5,如果大于0.5,则可以认为图片是我们要寻找的
如果类别很多,假设有1000个类别的ImageNet。如果要找概率最大的那个,可以使用np.argmax(probs)
如果要找概率前N大的,可以使用:argsort,如果是Tensor的话,可以直接使用:topk
import numpy as np
probs = np.array([8, 7, 1, 3, 0, 2, 5, 6, 4])
# 加了负号,是按降序排序
probs_idx_sort = np.argsort(-probs)
# 值前3大的是8,7,6,对应的索引是:[0 1 7]
print(probs_idx_sort[0:3])
对于分类模型的评估来说,有很多评价指标,例如准确率、精确率、召回率、F1-Score等。其中,最直观、最有说服力的就是精确率与召回率,这也是我在项目中观察的主要是指标
混淆矩阵
精确率与召回率就是通过混淆矩阵计算出来的
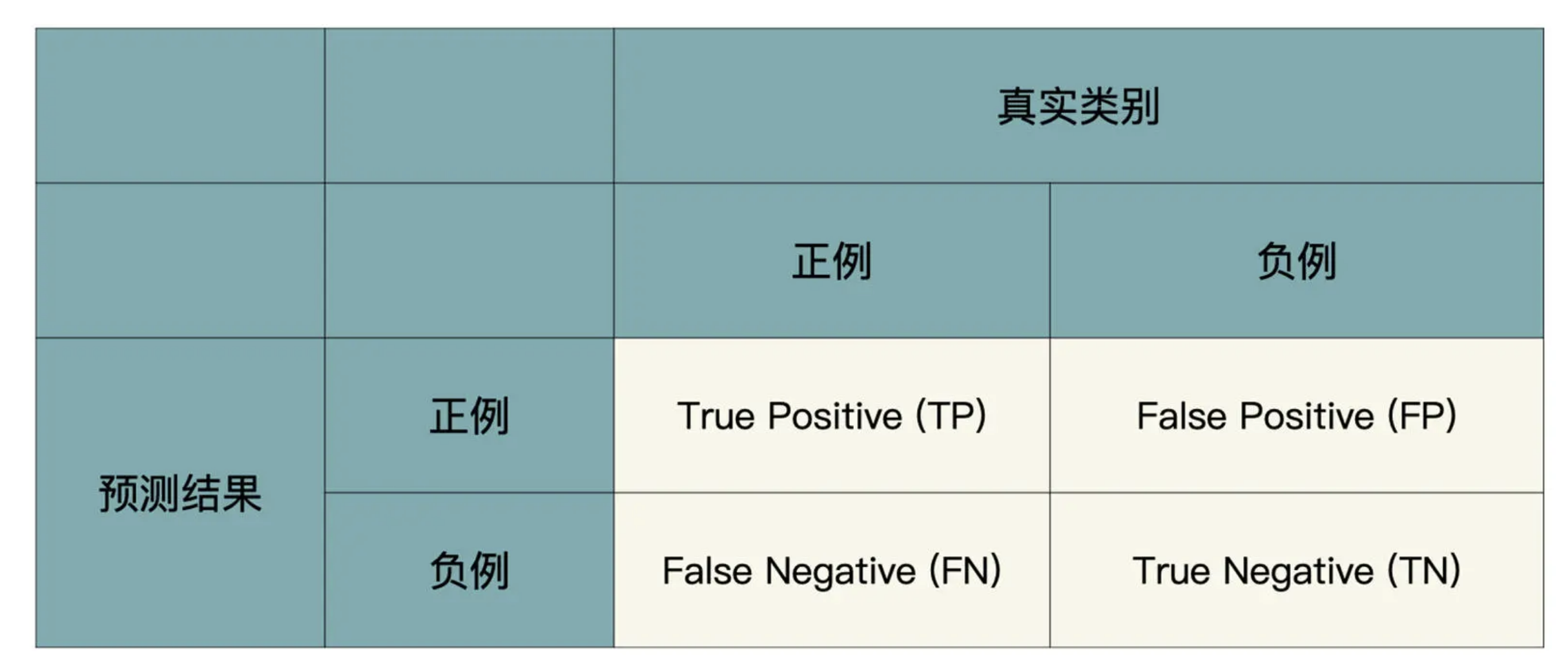
根据预测结果和真实类别的组合,一共有四种情况:
- TP是说真实类别为Logo,模型也预测为Logo;
- FP是说真实类别为Others,但模型预测为Logo;
- FN是说真实类别为Logo,但模型预测为Others;
- TN是说真实类别为Others,模型也预测为Others;
精确率的计算方法为:
召回率的计算方式为:
精确率与召回率分别衡量了模型的不同表现,精确率说的是,如果模型认为一张图片是A类,那有多大概率是A类。而召回率衡量的是,在整个验证集中,模型能找到多少A类图片
那问题来了,怎样根据这两个指标来选择模型呢?业务需求不同,我们侧重的指标就不一样
如果老板允许一部分A类图片没有被识别,但是模型必须非常准,模型说一张图片是A类,那图片真实类别就有非常大的概率是A类图片,那应该侧重的就是精确率;
如果老板希望把线上A类尽可能地识别出来,允许一部分图片被误识别,那应该侧重的就是召回率
在实际项目中,我们可以把模型对每张图片的预测结果保存到一个txt中,这样可以比较直观地筛选一些模型的badcase,并且验证集如果非常大,又需要调整的时候,直接更改txt就可以了,不需要再次让模型预测整个验证集
下面是txt文件的一部分,分别记录了A类的概率、others类的概率、真实类别是否为A、真实类别是否为others、预测类别是否为A、预测类别是否为ohters、图片名
0.64460 0.35540 1 0 1 0 ./data/val/class_a/13.jpeg
0.58476 0.41524 1 0 1 0 ./data/val/class_a/14.jpeg
...
原地操作
在PyTorch中,方法名末尾带有下划线(通常是一个或两个)往往表示该方法是原地操作(in-place operation)
原地操作是指该方法会直接修改输入张量(tensor)的内容,而不是返回一个新的张量。这种方式可以节省内存,因为不需要为结果分配额外的存储空间
例如,对于张量x,调用x.zero()会将x的所有元素设置为0,而不会返回一个新的全零张量。同样地,x.add(y)会将y的元素加到x上,并直接修改x的内容
固定随机种子
myseed = 42069
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed)