NLP
NLP(Natural Language Processing):自然语言处理,是计算机科学领域与人工智能领域中的一个重要方向
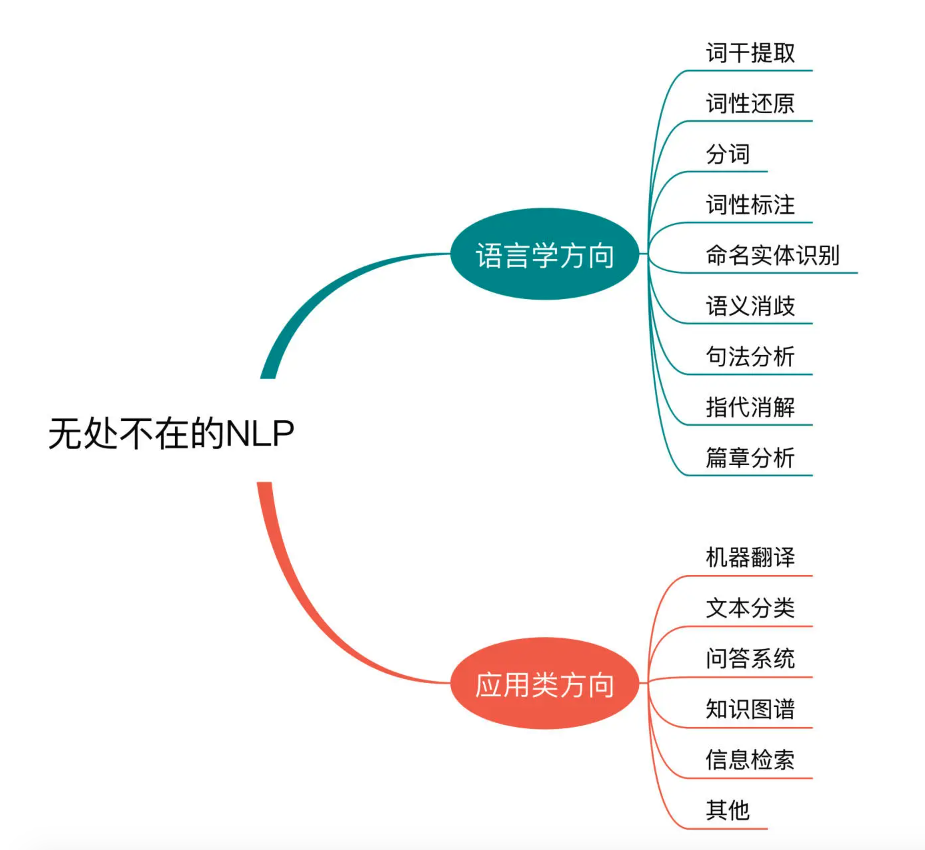
NLP研究的领域非常广泛,凡是跟语言学有关的内容都属于NLP的范畴。一般来说,较为多见的语言学的方向包括:词干提取、词形还原、分词、词性标注、命名实体识别、语义消歧、句法分析、指代消解、篇章分析等方面
NLP还有很多的研究内容是侧重“处理”和“应用”方面的,比如我们常见的就有:机器翻译、文本分类、问答系统、知识图谱、信息检索等
分词
常用NLP分词工具,比如jieba、HanLP、THULAC等
文本表示的方法
将token(分词或字符)映射到一个数字并计数,举例如下:
# token映射到数字
{
"张三": 1,
'李四': 2
}
# 数字映射到token
{
1: '张三',
2: '李四'
}
# token出现的次数
{
1: 3,
2: 1
}
但是上面那种表示方式,没有语序信息,所以现在深度学习的使用推动了 词嵌入(Word Embedding) 的发展,基本上我们都会采用该方法进行文本表示
关键词的提取
关键词,顾名思义,就是能够表达文本中心内容的词语。关键词提取在检索系统、推荐系统等应用中有着极重要的地位。它是文本数据挖掘领域的一个分支,所以在摘要生成、文本分类/聚类等领域中也是非常基础的环节
关键词提取,主要分为有监督和无监督的方法,一般来说,我们采用无监督的方法较多一些,这是因为它不需要人工标注的语料,只需要对文本中的单词按照位置、频率、依存关系等信息进行判断,就可以实现关键词的识别和提取
无监督方法常用的有三种类型,基于统计特征的方法、基于词图模型的方法,以及基于主题模型的方法
基于统计特征的方法
这种类型的方法最为经典的就是TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)。该方法最核心的思想非常简单:一个单词在文件中出现的次数越多,它的重要性越高;但它在语料库中出现的频率越高,它的重要性反而越小
基于词图模型的关键词提取
前面基于统计的方法采用的是对词语的频率计算的方式,但我们还可以有其他的提取思路,那就是基于词图模型的关键词提取
在这种方法中,我们首先要构建文本一个图结构,用来表示语言的词语网络。然后对语言进行网络图分析,在这个图上寻找具有重要作用的词或者短语,即关键词
该类方法中最经典的就是TextRank算法了,它脱胎于更为经典的网页排序算法PageRank
PageRank 的核心内容有两点:
- 如果一个网页被很多其他网页链接到的话,就说明这个网页比较重要,也就是PageRank值会相对较高
- 如果一个PageRank值很高的网页,链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高
而TextRank就非常好理解了。它跟PageRank的区别在于:
- 用句子代替网页
- 任意两个句子的相似性可以采用类似网页转换概率的概念计算,但是也稍有不同,TextRank用归一化的句子相似度代替了PageRank中相等的转移概率,所以在TextRank中,所有节点的转移概率不会完全相等
- 利用矩阵存储相似性的得分,类似于PageRank的矩阵M
- TextRank的基本流程如下图所示
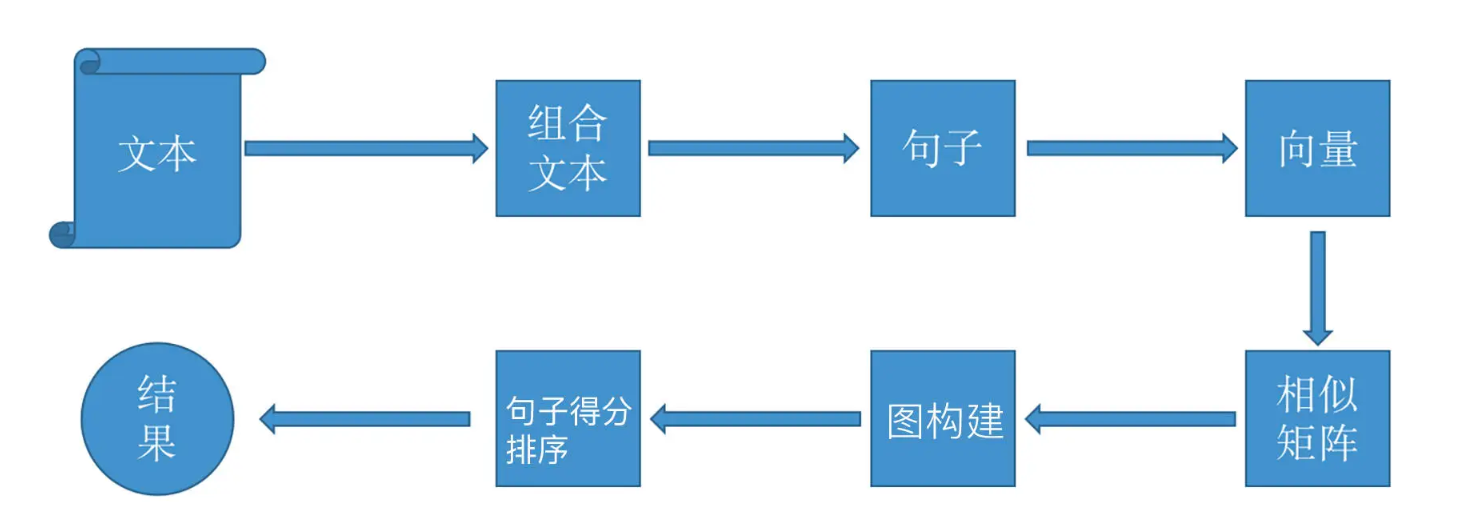
# 其中sentence是待处理的文本,topK是选择最重要的K个关键词,基本上用好这两个参数就够了
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False)
基于主题模型的关键词提取
主题模型,这个名字看起来就高端了很多,实际上它也是一种基于统计的模型,只不过它会“发现”文档集合中出现的抽象的“主题”,并用于挖掘文本中隐藏的语义结构
LDA(Latent Dirichlet Allocation)文档主题生成模型,是最典型的基于主题模型的算法。我们直接利用已经集成好的工具包gensim来实现使用这个模型
from gensim import corpora, models
import jieba.posseg as jp
import jieba
input_content = [line.strip() for line in open ('input.txt', 'r')]
# 分词
words_list = []
for text in input_content:
words = [w.word for w in jp.cut(text)]
words_list.append(words)
# 构建文本统计信息, 遍历所有的文本,为每个不重复的单词分配序列id,同时收集该单词出现的次数
dictionary = corpora.Dictionary(words_list)
# 构建语料,将dictionary转化为一个词袋
# corpus是一个向量的列表,向量的个数就是文档数。可以打印看一下它内部的结构
corpus = [dictionary.doc2bow(words) for words in words_list]
# 开始训练LDA模型
# 在训练环节中,num_topics代表生成的主题的个数。id2word即为dictionary,它把id都映射成为字符串。passes相当于深度学习中的epoch,表示模型遍历语料库的次数
lda_model = models.ldamodel.LdaModel(corpus=corpus, num_topics=8, id2word=dictionary, passes=10)
语言模型
分词、文本表示、关键词提取是NLP的三大经典问题,但它们并不能很好地将文本中单词、词组的顺序关系或者语义关系记录下来。也就是说,不能很好地量化表示,也不能对语言内容不同部分的重要程度加以区分
那么,有没有一种方法,可以把语言变成一种数学计算过程,比如采用概率、向量等方式对语言的生成和分析加以表示呢?答案当然是肯定的,这就是我们现在要讲的语言模型
那如何区分语言不同部分的重要程度呢?目前最火热的应该是注意力机制
语言模型是根据语言客观事实而进行的语言抽象数学建模,是一种对应关系。很多NLP任务中,都涉及到一个问题:对于一个确定的概念或者表达,判断哪种表示结果是最有可能的
我们结合两个例子体会一下
①. 翻译文字是:今天天气很好。可能的结果是:res1 = Today is a fine day. res2 = Today is a good day. 那么我们最后要的结果就是看概率P(res1)和P(res2)哪个更大
②. 问答系统提问:我什么时候才能成为亿万富翁。可能的结果有:ans1=白日做梦去吧。ans2=红烧肉得加点冰糖。那么,最后返回的答案就要选择最贴近问题内容本身的结果,这里就是前一个答案
对于上面例子中提到的问题,我们很自然就会联想到,可以使用概率统计的方法来建立一个语言模型,这种模型我们称之为统计语言模型
统计语言模型
统计语言模型的原理,简单来说就是计算一句话是自然语言(也就是一个正常句子)的概率。多年以来,专家学者构建出了非常多的语言模型,其中最为经典的就是基于马尔可夫假设n-gram语言模型,它也是被广泛采用的模型之一
给定一个句子,则生成该句子的概率为:,再由链式法则我们可以继续得到:。那么这个p(S)就是我们所要的统计语言模型
那么问题来了,你会发现从到无非是一个概率传递的过程,有一个非常本质的问题并没有被解决,那就是语料中数据必定存在稀疏的问题,公式中的很多部分是没有统计值的,那就成了0了,而且参数量真的实在是太大了
怎么办呢?我们观察一下后面这句话:“我们本节课将会介绍统计语言模型及其定义”。其中“定义”这个词,是谁的定义呢?是“其”的。那“其”又是谁呢?是前面的“语言模型”的。于是我们发现,对于文本中的一个词,它出现的概率,很大程度上是由这个单词前面的一个或者几个单词决定的,这就是马尔可夫假设
有了马尔可夫假设,我们就可以把前面的公式中的进一步简化,简化的程度取决于你认为一个单词是由前面的几个单词所决定的,如果只由前面的一个单词决定,那它就是,我们称之为bigram。如果由前面两个单词决定,则变为,我们称之为trigram
当然了,如果你认为单词的出现仅由其本身决定的,与其他单词无关,就变成了最简单的形式:,我们称之为unigram(一元模型)
那么现在我们知道了,基于马尔可夫链的统计语言模型,其核心就在于基于统计的条件概率。为了计算一个句子的生成概率,我们只需要统计每个词及其前面n个词的共现条件概率,再经过简单的乘法计算就可以得到最终结果了
神经网络语言模型
ngram模型一定程度上减少了参数的数量,但是如果n比较大,或者相关语料比较少的时候,数据稀疏问题仍然不能得到很好地解决
这就好比我们把水浒传的文本放入模型中进行统计训练,最后却问模型林冲和潘金莲的关系,这就很难回答了
因为基于ngram的统计模型实在是收集不到两者共现的文本。这种稀疏问题靠统计肯定不行了。那么怎么办呢?这时候就轮到神经网络语言模型闪亮登场了
其实从本质上说,神经网络语言模型也是通过ngram来进行语言的建模,但是神经网络的学习不是通过计数统计的方法,而是通过神经网络内部神经元针对数据不断更新
具体是怎么做的呢?首先我们要定义一个向量空间,假定这个空间是一百维的,这就意味着,对于每个单词,我们可以用一个一百维的向量对其进行表示,比如V(中国)=[0.2821289,0.171265,0.12378123,...,0.172364]
这样,对于任意两个单词,我们可以用距离计算的方式来评价它们之间的联系。比如我们使用cosin距离计算“中国”和“北京”两个单词的距离,就大概率要比“中国”和“西瓜”的距离要近得多
这样做有什么好处呢?首先,词与词之间的距离可以作为两个词之间相似性的度量。其次,向量空间隐含了很多的数学计算,比如经典的V(国王)-V(皇后)=V(男人)-V(女人),这让词语之间有了更多的语义上的关联
除了维度,为了确定向量空间,我们还需要确定这个空间有多少个“点”,也就是词语的数量有多少。一般来说,我们是将语料库中出现超过一定阈值次数的单词保留,把这些留下来的单词的数量,作为空间点的量了
我们具体看看实际的操作过程中是怎么做的。我们只需要建立一个M * N大小的矩阵,并随机初始化里面的每一个数值,其中M表示的是词语的数量,N表示词语的维度。我们把这样矩阵叫做词向量矩阵

既然是随机初始化的,那么就意味着这个向量空间不能作为我们的语言模型使用。下面我们就要想办法让这个矩阵学到内容。如下图:
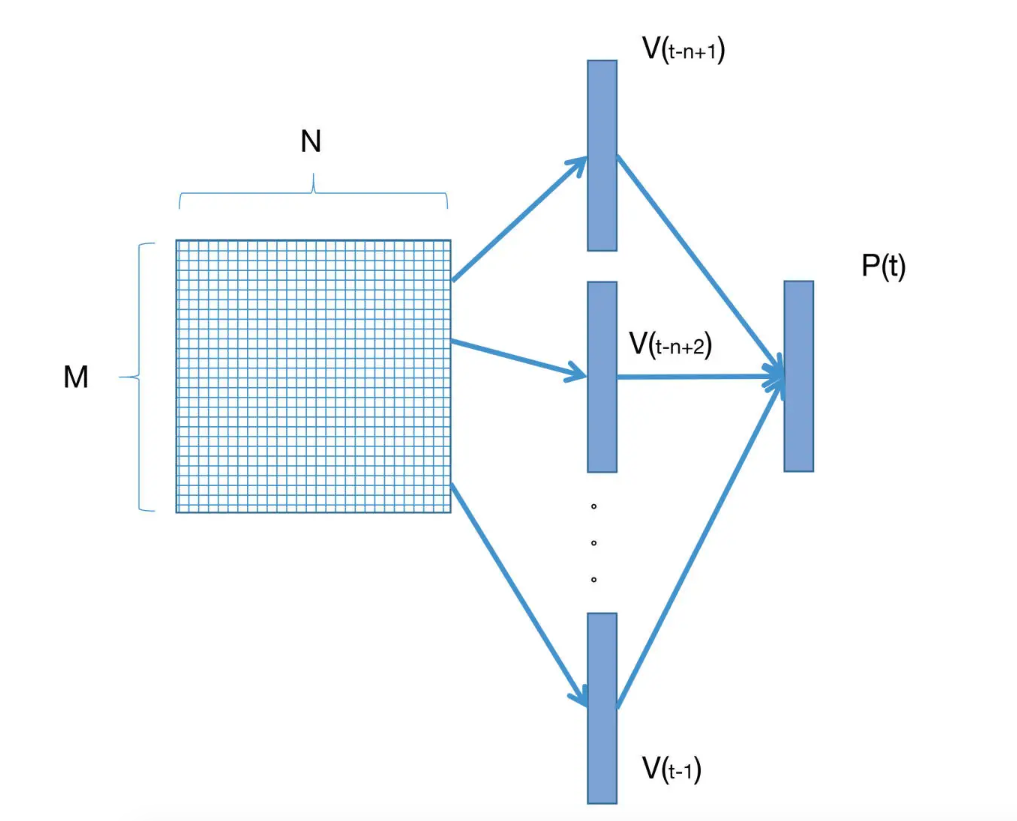
刚才我们说过,神经网络语言模型也是通过ngram来进行语言建模的。假定我们的ngram长度为n,那么我们就从词向量矩阵中找到对应的前n-1个词的向量,经过若干层神经网络(包括激活函数),将这n-1个词的向量映射到对应的条件概率分布空间中。最后,模型就可以通过参数更新的方式,学习词向量的映射关系参数,以及上下文单词出现的条件概率参数了
简单来说就是,我们使用n-1个词,预测第n个词,并利用预测出来的词向量跟真实的词向量做损失函数并更新,就可以不断更新词向量矩阵,从而获得一个语言模型。这种类型的神经网络语言模型我们称之为前馈网络语言模型
除了前馈网络语言模型,还有一种叫做基于LSTM的语言模型。下一章节,我们将会通过LSTM完成情感分析任务的项目,进一步细化LSTM神经网络语言模型的训练过程,同时也会用到前面提到的词向量矩阵
现在,我们回过头来比较一下统计语言模型和神经网络语言模型的区别。统计语言模型的本质是基于词与词共现频次的统计,而神经网络语言模型则是给每个词分别赋予了向量空间的位置作为表征,从而计算它们在高维连续空间中的依赖关系。相对来说,神经网络的表示以及非线性映射,更加适合对自然语言进行建模
注意力机制
如果你足够细心就会发现,在前面介绍的神经网络语言模型中,我们似乎漏掉了一个点,那就是,对于一个由n个单词组成的句子来说,不同位置的单词,重要性是不一样的。因此,我们需要让模型“注意”到那些相对更加重要的单词,这种方式我们称之为注意力机制,也称作Attention机制
既然是机制,它就不是一个算法,准确来说是一个构建网络的思路。关于注意力机制最经典的论文就是大名鼎鼎的《Attention Is All You Need》
我们从一个例子入手,比如“我今天中午跑到了肯德基吃了仨汉堡”。这句话中,你一定对“我”、“肯德基”、“仨”、“汉堡”这几个词比较在意,不过,你是不是没注意到“跑”字?
其实Attention机制要做的就是这件事:找到最重要的关键内容。它对网络中的输入(或者中间层)的不同位置,给予了不同的注意力或者权重,然后再通过学习,网络就可以逐渐知道哪些是重点,哪些是可以舍弃的内容了
在前面的神经网络语言模型中,对于一个确定的单词,它的向量是固定的,但是现在不一样了,因为Attention机制,对于同一个单词,在不同语境下它的向量表达是不一样的
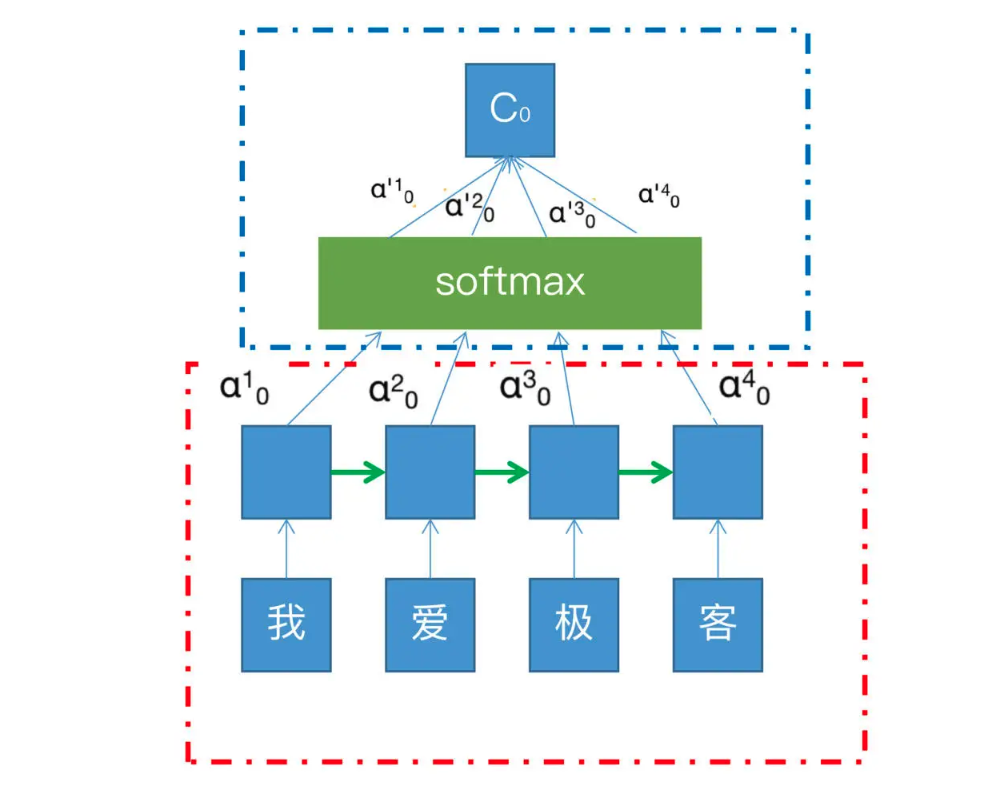
下面这张图是Attention机制和RNN结合的例子。其中红色框中的是RNN的展开模式,我们可以看到,我/爱/极/客四个字的向量沿着绿色箭头的方向传递,每个字从RNN节点出来之后都会有一个隐藏状态h,也就是输入节点上面的蓝色方框,在这个过程中每个状态的权重是一样的,不分大小
而蓝色框就是Attention机制所加入的部分,其中的每个α就是每个状态h的权重,有了这个权重,就可以将所有的状态h,加权汇总到softmax中,然后求和得到最终输出C。这个C就可以为后续的RNN判断权重,提供更多的计算依据
注意力机制的原理其实很简单,但是也很巧妙。只需要增加很少的参数,就可以让模型自己弄清楚谁重要谁次要。那么下面我们来看一下抽象化之后的Attention,如下图

在这里输入是query(Q),key(K),value(V),输出是attention value。跟刚才Attention与RNN结合的图类比,query就是上一个时间节点传递进来的状态,而这个就是上一个时间节点输出的编码。key就是各个隐藏状态h,value也是隐藏状态。模型通过Q和K的匹配公式计算出权重,再同V结合就可以得到输出,这就相当于计算得到了当前的输出和所有输入的匹配度,公式如下:
Attention目前主要有两种,一种是soft attention,一种是hard attention。hard attention关注的是当前词附近很小的一个区域,而soft attention则是关注了更大更广的范围,也更为常用