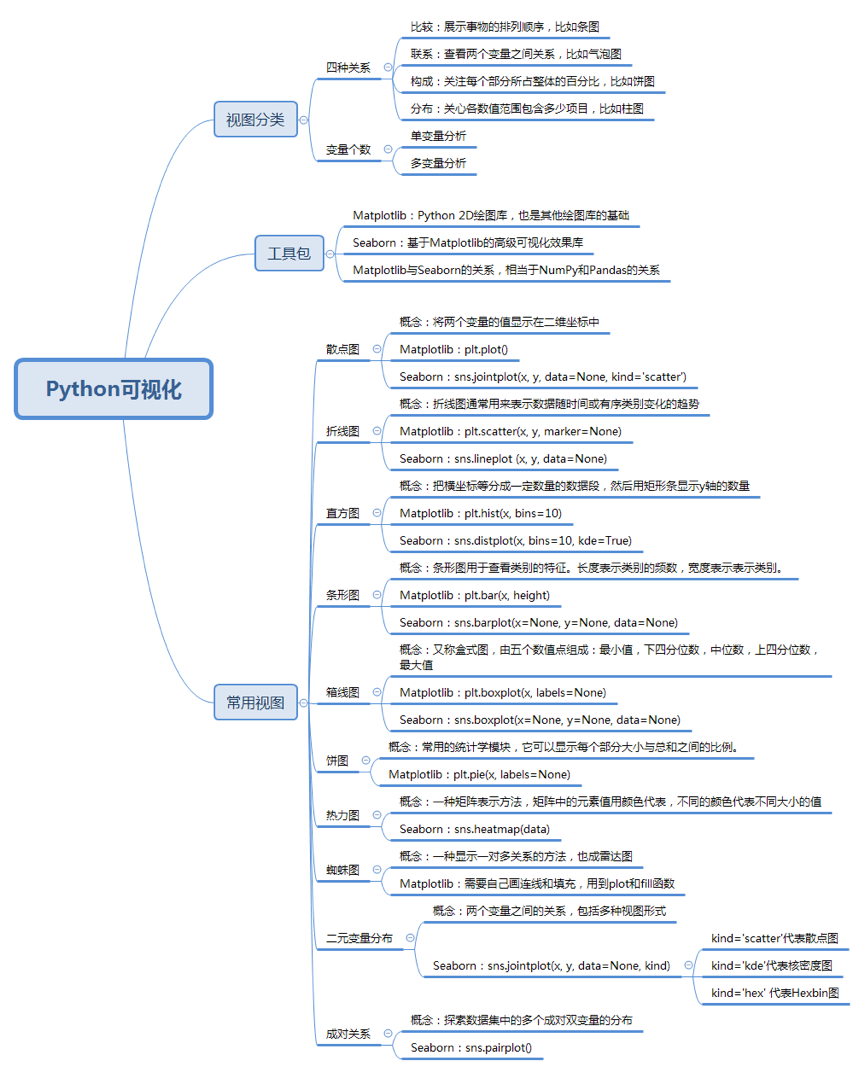
python可视化
Python常用的可视化工具包包括:Matplotlib和Seaborn
他们两者之间的关系就相当于NumPy和Pandas的关系
Seaborn是基于Matplotlib更加高级的可视化库
Matplotlib
约定俗成的引入方式:import matplotlib.pyplot as plt
Seaborn
约定俗成的引入方式:import seaborn as sns
至于为什么叫sns有2种说法
- sns可以理解为:seaborn space(seaborn命名空间)的缩写
- 美剧The West Wing里有一个人物名叫Samuel Norman Seaborn, 首字母简写为SNS
当然,如果你是一个不按规矩出牌的人,你要叫sb也是可以的
折线图
以折线的上升或下降来表示统计数量的增减变化的统计图
特点:能够显示数据的变化趋势,反映事物的变化情况(变化)
import matplotlib.pyplot as plt
# 数据准备,x最好是升序的,否则画出来的就不是折线图
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
# 使用Matplotlib画折线图
plt.plot(x, y)
plt.show()
子图
如果在有子图的场景,直接使用plt.plot()等,默认是在最后一张图上生效(一般不建议这样隐式操作)
nrows:子图的行数ncols:子图的列数sharex:所有子图使用相同的x轴刻度(调整xlim会影响所有子图)sharey:所有子图使用相同的y轴刻度(调整ylim会影响所有子图)subplot_kw:传入add_subplot的关键字参数字典,用于生成子图**fig_kw:在生成图片时使用的额外关键字参数,例如:plt.subplots(2,2,figsize=(8,6))
默认情况下,matplotlib会在子图的外部和子图之间留出一定的间距。这个间距都是相对于图的高度和宽度来指定的,如果你通过编程或手动使用GUI窗口来调整图的太小,那么图就会自动调整
你可以使用图对象上的subplots_adjust方法更改间距,也可以用作顶层函数plt.subplots_adjust
import matplotlib.pyplot as plt
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
fig = plt.figure(figsize=(8, 4), dpi=200)
# 2行1列的第1个
ax1 = fig.add_subplot(2, 1, 1)
# 2行1列的第2个
ax2 = fig.add_subplot(2, 1, 2)
ax1.plot(x, y)
ax2.plot(x, y)
plt.show()
# 子图是比较常用的功能,所以plt提供了subplots方法
# axes是根据行列的维度生成的n行n列的ndarray
fig, axes = plt.subplots(2, 3, sharex=True, sharey=True)
# 这里不要用迭代的方式遍历,否则ax_item会被覆盖
indexes = axes.shape
for i in range(indexes[0]):
for j in range(indexes[1]):
axes[i][j].plot(x, y)
# subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=None)
# wspace和hspace分别控制图片的宽高百分比,以用作子图的间距
plt.subplots_adjust(wspace=0, hspace=0)
plt.show()
样式
具体可查看matplotlib文档
import matplotlib.pyplot as plt
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
fig, axes = plt.subplots(2, 3)
# 绿色虚线
axes[0, 0].plot(x, y, color='g', linestyle='--')
# 绿色点点线
axes[0, 1].plot(x, y, color='green', linestyle=':')
# 绿色加粗虚线(带网格线、x轴标签、y轴标签、总标题)
axes[0, 2].plot(x, y, color='#00ff00', linestyle='--', linewidth=5)
axes[0, 2].grid(alpha=0.3, linestyle=":")
axes[0, 2].set_xlabel("year", fontsize='small')
axes[0, 2].set_ylabel("sales volume", fontsize='small')
axes[0, 2].set_title("year sales volume summary", fontsize='small')
# 黑色虚线
axes[1][0].plot(x, y, 'k--')
# 黑色虚线带点
axes[1][1].plot(x, y, 'ko--')
# 黑色透明度虚线带点(折线图后面的点默认是线性内插的,可以通过drawstyle选项更改)
axes[1][2].plot(x, y, color='black', linestyle='dashed', marker='o', alpha=0.3, drawstyle='steps-post')
plt.show()
刻度、标签
xlim、xticks、xticklabels分别控制了x轴的绘图范围、刻度位置、刻度标签
当它们不传入参数的话,比如:plt.xlim()返回当前x轴的绘图范围
如果在子图中,分别对应get_xxx和set_xxx,比如:ax.set_xlim([0, 1000])
同理,如果在子图中找不到相关函数,可以加set_试下,如:set_xlabel、set_ylabel、set_title等
子图中所有set相关,可以用set一个字典来实现,如:ax.set(**props)
import matplotlib.pyplot as plt
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
plt.plot(x, y)
# 没有参数,返回当前x轴绘图范围 (2009.45, 2021.55)
print(plt.xlim())
# 设置y轴范围
plt.ylim([0, 1000])
# 设置y轴刻度、标签、旋转、字体样式
plt.yticks(range(0, 2001, 500), [0, '0.5k', '1k', '1.5k', '2k'], rotation=30, fontsize='small')
# 子图中使用get_xxx、set_xxx
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(x, y)
# 设置y轴刻度范围
ax.set_ylim([0, 2000])
# 设置y轴刻度位置
ax.set_yticks(range(0, 2001, 500))
# 设置y轴刻度标签,旋转30度,字体样式:小
ax.set_yticklabels([0, '0.5k', '1k', '1.5k', '2k'], rotation=30, fontsize='small')
plt.show()
如果对刻度没有极致的自定义需求的话,也可以使用下面的方式设置
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
y = [i * 1000000 for i in y]
def parse_million(value, position):
return '{}m'.format(int(value / 1000000))
def parse_thousand(value, position):
return '{}k'.format(int(value / 1000))
def factory(flag):
if flag == 'million':
return parse_million
elif flag == 'thousand':
return parse_thousand
plt.gca().yaxis.set_major_formatter(FuncFormatter(factory('million')))
plt.plot(x, y)
plt.show()
图例
import matplotlib.pyplot as plt
import numpy as np
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
y1 = np.array([5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]) * 10
y2 = np.array([5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]) + 100
y3 = np.array([5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]) + 200
plt.plot(x, y, label='y sales volume')
plt.plot(x, y1, label='y1 sales volume')
plt.plot(x, y2)
plt.plot(x, y3, label='_nolegend_')
# 右上
# plt.legend(loc='upper right')
# 最佳位置(y2、y3不会显示在图例中,因为它们没有标签或显示指定了:_nolegend_)
plt.legend(loc='best')
plt.show()
注释与子图加工
注释可能包含:文本、箭头、其他图形,分别对应:text、arrow、annote
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from datetime import date, datetime
nsteps = 100
draws = np.random.randint(0, 2, size=nsteps)
steps = np.where(draws > 0, 1, -1)
walk = steps.cumsum()
df = pd.DataFrame({'walk': walk}, index=pd.date_range(
'2023-01-01', periods=nsteps))
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# 直接用Series.plot,图片的坐标轴有点问题
# df['walk'].plot(ax=ax)
ax.plot(df.index, df['walk'])
ax.set_xlim([date(2023, 1, 1), date(2023, 4, 30)])
dt = pd.date_range('2023-01-01', periods=4, freq='MS')
ax.set_xticks(dt)
ax.set_xticklabels(dt.strftime("%Y%m%d"))
# x轴、y轴、文本注释、字体、字体大小
ax.text(date(2023, 1, 1), df['walk'].iloc[0],
'start date', family='monospace', fontsize=10)
data = [
(datetime(2023, 1, 10), 'text in 1/10'),
(datetime(2023, 2, 10), 'text in 2/10'),
(datetime(2023, 3, 10), 'text in 3/10'),
]
# 文本注释、xy=箭头的xy轴坐标(如果只有前2个参数,那就是文本注释的xy轴坐标)、arrowprops=箭头、xytext=文本注释的xy轴坐标、horizontalalignment=水平对齐、verticalalignment=垂直对齐
for date, label in data:
ax.annotate(label, xy=(date, df['walk'].asof(date)), arrowprops=dict(facecolor='black', headwidth=4, width=2, headlength=4), xytext=(
date, df['walk'].asof(date)+2), horizontalalignment='left', verticalalignment='top')
plt.show()
绘制图形
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# 矩形,左下角坐标、宽度、长度、颜色、透明度
rect = plt.Rectangle((0.2, 0.75), 0.4, 0.15, color='red', alpha=0.3)
# 圆形(画出来是椭圆,因为xy轴比例不是1:1),圆心坐标、半径、颜色、透明度
circ = plt.Circle((0.7, 0.2), 0.15, color='blue', alpha=0.3)
# 多边形,三个点形成三角形、颜色、透明度
pgon = plt.Polygon([(0.15, 0.15), (0.35, 0.4), (0.2, 0.6)],
color="green", alpha=0.3)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)
plt.show()
保存图片
- fname:包含文件路径或Python文件型对象的字符串。图片格式是从文件扩展名中推断出来的(例如PDF格式的.pdf或PNG格式的.png)
- dpi:每英寸点数的分辨率;默认值100
- facecolor、edgecolor:子图之外的图形背景的颜色;默认值'w'(白色)
- format:文件格式('png','pdf','svg','ps','eps'...)
- bbox_inches:要保存的图片范围;如果传递'tight',将会去除掉图片周围的空白的部分
import matplotlib.pyplot as plt
from io import BytesIO
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
rect = plt.Rectangle((0.2, 0.75), 0.4, 0.15, color='red', alpha=0.3)
ax.add_patch(rect)
# 保存图片
plt.savefig('test.svg', dpi=400, bbox_inches='tight')
# savefig并不一定要将图片写到硬盘,它可以将图片写入到所有的文件型对象中,例如:BytesIO
buffer = BytesIO()
plt.savefig(buffer)
plot_data = buffer.getvalue()
print(plot_data)
全局设置
如果需要更深入定制和参看全量选项,可以参考site-packages/matplotlib/mpl-data/matplotlibrc
如果你定制了这个文件,并将他放置在Home路径下并且命名为.matplotlibrc,则每次使用matplotlib时都会读取该文件
如果系统没有相关中文字体或者matplotlib无法找到,可以下载或复制字体到,site-packages/matplotlib/mpl-data/matplotlibrc/fonts路径下
import matplotlib.pyplot as plt
# 第一个参数是想要自定义的组件,比如:figure、axes、xtick、ytick、grid、legend
# 后面的参数是组件相关的参数
plt.rc('figure', figsize=(10, 10), dpi=100)
# 也可以按照关键字参数的序列指定新参数
font_options = {
'family': 'Hei', # 中文黑体(windows用SimHei,mac用:Hei,具体根据本地环境来)
'weight': 'bold',
'size': 10
}
plt.rc('font', **font_options)
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
plt.plot(x, y)
plt.title('你好,世界')
plt.xlabel("年份")
plt.ylabel("销量")
y_ticks = [0, 200, 400, 600, 800, 1000]
plt.yticks(y_ticks, [f'{i}万' for i in y_ticks])
plt.show()
中文字体
优先使用rc的方式全局设置,如果全局设置无效的话,可以使用以下方式设置
查看中文字体路径
关于本机 -> 系统报告 -> 软件 -> 字体
fc-list :lang=zh
import matplotlib.pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(
fname=r"/Library/Fonts/Microsoft/SimHei.ttf", size=14)
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
plt.plot(x, y)
plt.title('你好,世界', fontproperties=my_font)
plt.xlabel("年份", fontproperties=my_font)
plt.ylabel("销量", fontproperties=my_font)
y_ticks = [0, 200, 400, 600, 800, 1000]
plt.yticks(y_ticks, [f'{i}万' for i in y_ticks], fontproperties=my_font)
plt.show()
折线图
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备,x最好是升序的,否则画出来的就不是折线图
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35, 666, 888]
# 使用Seaborn画折线图
df = pd.DataFrame({'x': x, 'y': y})
sns.lineplot(x="x", y="y", data=df)
plt.show()
散点图
用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式
特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备,随机1000个x,y坐标
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
# 用Matplotlib画散点图,marker='o'代表使用圆点标记
plt.scatter(x, y, marker='o')
plt.show()
# 用Seaborn画散点图
df = pd.DataFrame({'x': x, 'y': y})
sns.jointplot(x="x", y="y", data=df, kind='scatter')
plt.show()
直方图
由一系列高度不等的纵向条纹或线段表示数据分布的情况,一般用横轴表示数据范围,纵轴表示分布情况
特点:绘制连续性的数据,展示一组或多组数据的分布情况(统计)
hist方法适合对原始数据进行直方图的绘制,如果是分组好的数据使用条形图的方法绘制(调整宽度让图形连续即可)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
a = np.random.randn(100)
s = pd.Series(a)
# 用Matplotlib画直方图,bins默认10,可不填
plt.hist(s, bins=10)
plt.show()
# 用Seaborn画直方图,bins默认10,可不填
sns.histplot(s, kde=False, bins=10)
plt.show()
# kde为True表示显示折线图,默认为True
sns.histplot(s, kde=True, bins=10)
plt.show()
条形图
排列在工作表的列或行中的数据可以绘制到条形图中
特点:绘制离散的数据,能够一眼看出各个数据的大小、比较数据之间的差别(统计)
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 数据准备
x = ['Cat1', 'Cat2', 'Cat3', 'Cat4', 'Cat5']
y = [5, 4, 8, 12, 7]
# 用Matplotlib画条形图,x为横坐标分类名,y为纵坐标分类值
plt.bar(x, y)
plt.show()
# 用Seaborn画条形图
df = pd.DataFrame({'x': x, 'y': y})
sns.barplot(x="x", y="y", data=df)
plt.show()
横着的条形图
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='/System/Library/Fonts/Supplemental/Songti.ttc')
a = ["战狼2", "速度与激情8", "功夫瑜伽", "西游伏妖篇", "变形金刚5:最后的骑士", "摔跤吧!爸爸", "加勒比海盗5:死无对证", "金刚:骷髅岛", "极限特工:终极回归", "生化危机6:终章",
"乘风破浪", "神偷奶爸3", "智取威虎山", "大闹天竺", "金刚狼3:殊死一战", "蜘蛛侠:英雄归来", "悟空传", "银河护卫队2", "情圣", "新木乃伊", ]
b = [56.01, 26.94, 17.53, 16.49, 15.45, 12.96, 11.8, 11.61, 11.28, 11.12, 10.49, 10.3, 8.75, 7.55, 7.32, 6.99, 6.88,
6.86, 6.58, 6.23]
plt.barh(a, b, color='orange', height=0.3)
plt.yticks(a, fontproperties=my_font)
plt.show()
箱线图
箱线图,又称盒式图,它是在1977年提出的,由五个数值点组成:最大值(max)、最小值(min)、中位数(median)和上下四分位数(Q3,Q1)
它可以帮我们分析出数据的差异性、离散程度和异常值等
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 数据准备,生成10*4维度数据
data = np.random.normal(size=(10, 4))
labels = ['A', 'B', 'C', 'D']
# 用Matplotlib画箱线图
plt.boxplot(data, labels=labels)
plt.show()
# 用Seaborn画箱线图
df = pd.DataFrame(data, columns=labels)
sns.boxplot(data=df)
plt.show()
饼图
饼图是常用的统计学模块,可以显示每个部分大小与总和之间的比例
import matplotlib.pyplot as plt
# 数据准备
nums = [25, 37, 33, 37, 6]
labels = ['High-school', 'Bachelor', 'Master', 'Ph.d', 'Others']
# 用Matplotlib画饼图
plt.pie(x=nums, labels=labels)
plt.show()
热力图
热力图,英文叫heat map,是一种矩阵表示方法,其中矩阵中的元素值用颜色来代表,不同的颜色代表不同大小的值
通过颜色就能直观地知道某个位置上数值的大小。另外你也可以将这个位置上的颜色,与数据集中的其他位置颜色进行比较
热力图是一种非常直观的多元变量分析方法
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备,seaborn自带的数据集flights,该数据集记录了1949年到1960年期间,每个月的航班乘客的数量
flights = sns.load_dataset("flights")
data = flights.pivot('year', 'month', 'passengers')
# 用Seaborn画热力图
sns.heatmap(data)
plt.show()
蜘蛛图
蜘蛛图是一种显示一对多关系的方法。在蜘蛛图中,一个变量相对于另一个变量的显著性是清晰可见的
假设我们想要给王者荣耀的玩家做一个战力图,指标一共包括推进、KDA、生存、团战、发育和输出
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 数据准备,labels标签名,stats标签值
labels = np.array([u"推进", "KDA", u"生存", u"团战", u"发育", u"输出"])
stats = [83, 61, 95, 67, 76, 88]
# 画图数据准备,角度
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False)
# 数组上增加一位,也就是添加数组的第一个元素,形成一个环
stats = np.concatenate((stats, [stats[0]]))
angles = np.concatenate((angles, [angles[0]]))
labels = np.concatenate((labels, [labels[0]]))
# 用Matplotlib画蜘蛛图,创建一个空白的figure对象,相当于画画前先准备一个空白的画板
fig = plt.figure()
# 111,把画板划分成1行1列
ax = fig.add_subplot(111, polar=True)
# plot、fill,连线以及绘图上色
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
# 设置中文字体
font = FontProperties(fname=r"/Users/tangxiaofeng/data/font/simhei.ttf", size=14)
# 设置标签
ax.set_thetagrids(angles * 180 / np.pi, labels, font_properties=font)
plt.show()
二元变量分布
如果我们想要看两个变量之间的关系,就需要用到二元变量分布。当然二元变量分布有多种呈现方式,散点图就是一种二元变量分布
- 在Seaborn里,使用二元变量分布是非常方便的,直接使用sns.jointplot(x,y,data=None,kind)函数即可
- “kind='scatter'”代表散点图
- “kind='kde'”代表核密度图
- “kind='hex'”代表Hexbin图,它代表的是直方图的二维模拟
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备,使用seaborn自带的模拟数据
tips = sns.load_dataset("tips")
# 用Seaborn画二元变量分布图(散点图,核密度图,Hexbin图)
sns.jointplot(x="total_bill", y="tip", data=tips, kind='scatter')
sns.jointplot(x="total_bill", y="tip", data=tips, kind='kde')
sns.jointplot(x="total_bill", y="tip", data=tips, kind='hex')
plt.show()
成对关系
如果想要探索数据集中的多个成对双变量的分布,可以直接采用sns.pairplot()函数
它会同时展示出DataFrame中每对变量的关系,另外在对角线上,你能看到每个变量自身作为单变量的分布情况
它可以说是探索性分析中的常用函数,可以很快帮我们理解变量对之间的关系
pairplot函数的使用,就像在DataFrame中使用describe()函数一样方便,是数据探索中的常用函数
import matplotlib.pyplot as plt
import seaborn as sns
# 数据准备
iris = sns.load_dataset('iris')
# 用Seaborn画成对关系
sns.pairplot(iris)
plt.show()