经典网络
工作当中,我们很少从0到1自创一个网络模型,常常是在经典设计基础上做一些自定义配置,所以我们最好对这些经典网络都有所了解
VGG
VGG 取得了 ILSVRC 2014比赛分类项目的第2名和定位项目的第1名的优异成绩
当年的VGG一共提供了A到E 6种不同的VGG网络(字母不同,只是表示层数不一样)。VGG19的效果虽说最好,但是综合模型大小等指标,在实际项目中VGG16用得更加多一点。具体的网络结构可以看看论文
VGG突破的一些重点:
- 证明了随着模型深度的增加,模型效果也会越来越好
- 使用较小的3×3的卷积,代替了AlexNet中的11×11、7×7以及5×5的大卷积核
VGG中将5×5的卷积用2层3×3的卷积替换;将7×7的卷积用3层3×3的卷积替换。这样做首先可以减少网络的参数,其次是可以在相同感受野的前提下,加深网络的层数,从而提取出更加多样的非线性信息
GoogLeNet
2014年分类比赛的冠军是GoogLeNet。GoogLeNet的核心是Inception模块。这个时期的Inception模块是v1版本,后续还有v2、v3以及v4版本
我们先来看看GoogLeNet解决了什么样的问题。研究人员发现,对于同一个类别的图片,主要物体在不同图片中,所占的区域大小均有不同,如下图所示:

如果使用AlexNet或者VGG中标准的卷积的话,每一层只能以相同的尺寸的卷积核来提取图片中的特征
但是正如上图所示,很可能物体以不同的尺寸出现在图片中,那么能否以不同尺度的卷积来提取不同的特征呢?沿着这个想法,Inception模块应运而生,如下图示:

结合图示我们发现,这里是将原来的相同尺寸卷积提取特征的方式拆分为,使用1×1、3×3、5×5以及3×3的max pooling同时进行特征提取,然后再合并到一起。这样就做到了以多尺度的方式提取图片中的特征
作者为了降低网络的计算成本,将上述的Inception模块做了一步改进,在3×3、5×5之前与pooling之后添加了1×1卷积用来降维,从而获得了Inception模块的最终形态
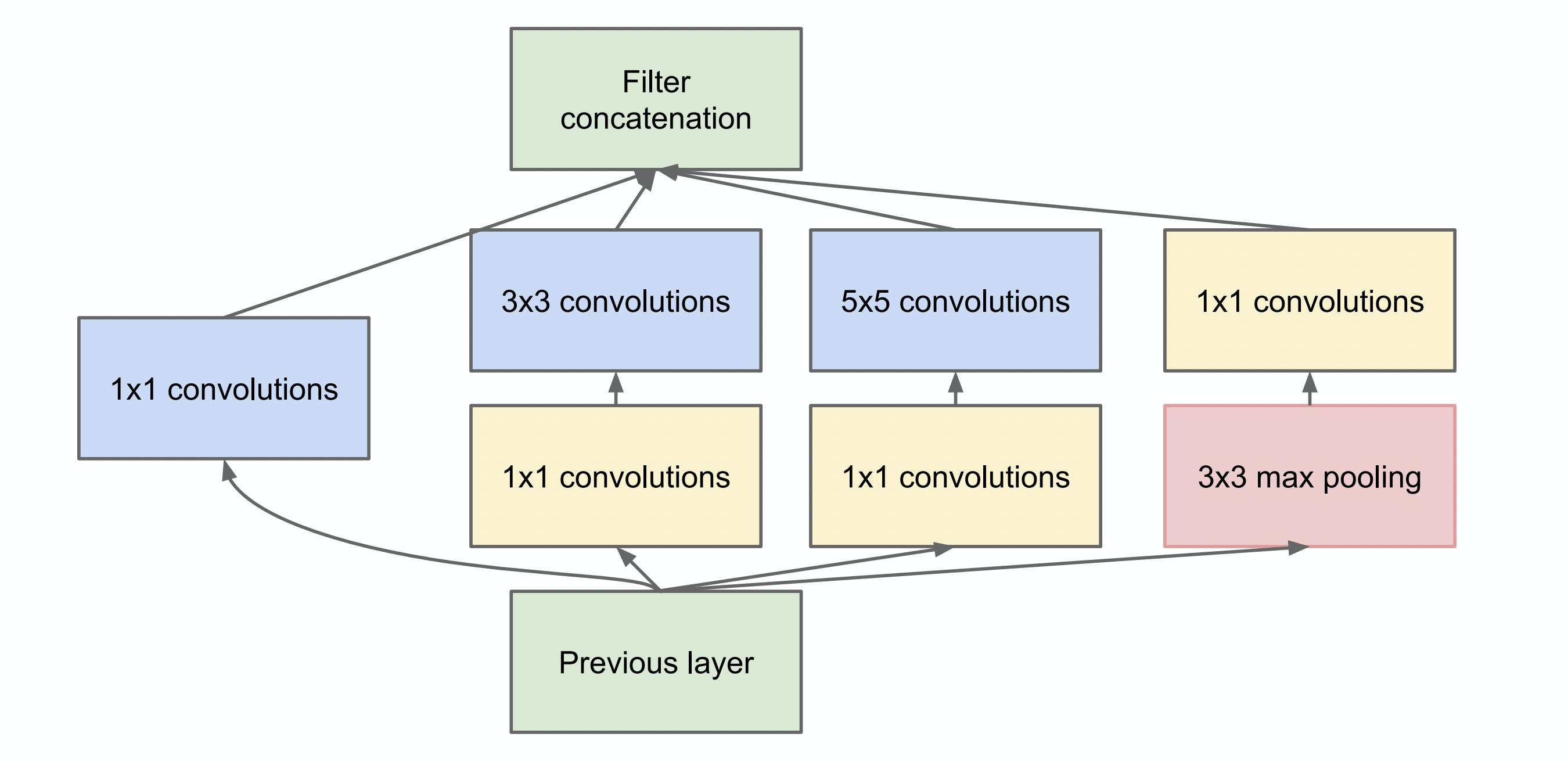
如果是面试,经常会被问到为什么采用1×1的卷积或者1×1卷积的作用。1×1卷积的作用就是用来升维或者降维的
GooLeNet就是由以上的Inception模块构成的一个22层网络。别看网络层数有22层,但是它参数量却比AlexNet与VGG都要少,这带来的优势就是,搭建起来的模型就很小,占的存储空间也小。具体的网络结构可以参考它的论文
ResNet
ResNet中文意思是残差神经网络。在2015年的ImageNet比赛中,模型的分类能力首次超越人眼,1000类图片top-5的错误率降低到3.57%
在论文中作者给出了18层、34层、50层、101层与152层的ResNet。101层的与152层的残差神经网络效果最好,但是受硬件设备以及推断时间的限制,50层的残差神经网络在实际项目中更为常用
网络退化问题
虽说研究已经证明,随着网络深度的不断增加,网络的整体性能也会提升。如果只是单纯的增加网络,就会引起以下两个问题:第一,模型容易过拟合;第二,产生梯度消失、梯度爆炸的问题
虽然随着研究的不断发展,以上两个问题都可以被解决掉,但是ResNet网络的作者发现,以上两个问题被规避之后,简单的堆叠卷积层,依然不能获得很好的效果
为了验证刚才的观点,作者做了这样的一个实验。通过搭建一个普通的20层卷积神经网络与一个56层的卷积神经网络,在CIFAR-10数据集上进行了验证。无论训练集误差还是测试集误差,56层的网络均高于20层的网络。下图来源于论文

出现这样的情况,作者认为这是网络退化造成的
网络退化是指当一个网络可以开始收敛时,随着网络层数的增加,网络的精度逐渐达到饱和,并且会迅速降低。这里精度降低的原因并不是过拟合造成的,因为如果是过拟合,上图中56层的在训练集上的精度应该高于20层的精度
作者认为这一现象并不合理,假设20层是一个最优的网络,通过加深到56层之后,理论上后面的36层是可以通过学习到一个恒等映射的,也就是说理论上不会学习到一个比26层还差的网络
所以,作者猜测网络不能很容易地学习到恒等映射(恒等映射就是f(x)=x)
残差学习
从网络退化问题中可以发现,通过简单堆叠卷积层似乎很难学会到恒等映射。为了改善网络退化问题,论文作者何凯明提出了一种深度残差学习的框架
因为网络不容易学习到恒等映射,所以就让它强制添加一个恒等映射,如下图所示(下图来源于论文)

具体实现是通过一种叫做shortcut connection的机制来完成的。在残差神经网络中shortcut connection就是恒等变换,就是上图中带有x identity的那条曲线,包含shortcut connection的几层网络我们称之为残差块
残差块被定义为如下形式:
F可以是2层的卷积层。也可以是3层的卷积层。最后作者发现,通过残差块,就可以训练出更深、更加优秀的卷积神经网络了
EfficientNet
EfficientNet为我们提供了B0~B7,一共8个不同版本的模型,参数量由少到多,精度也越来越高,在同等参数量的模型中,它的精度都是首屈一指的。因此,这8个版本的模型可以解决你的大多数问题
在之前的那些网络,要么从网络的深度出发,要么从网络的宽度出发来优化网络的性能,但从来没有人将这些方向结合在一起考虑。而EfficientNet就做了这样的尝试,它探索了网络深度、网络宽度、图像分辨率之间的最优组合
EfficientNet利用一种复合的缩放手段,对网络的深度depth、宽度width和分辨率resolution同时进行缩放(按照一定的缩放规律),来达到精度和运算复杂度FLOPS的权衡
但即使只探索这三个维度,搜索空间仍然很大,所以作者规定只在B0(作者提出的EfficientNet的一个Baseline)上进行放大
首先,作者比较了单独放大这三个维度中的任意一个维度效果如何。得出结论是放大网络深度或网络宽度或图像分辨率,均可提升模型精度,但是越放大,精度增加越缓慢,如下图所示:
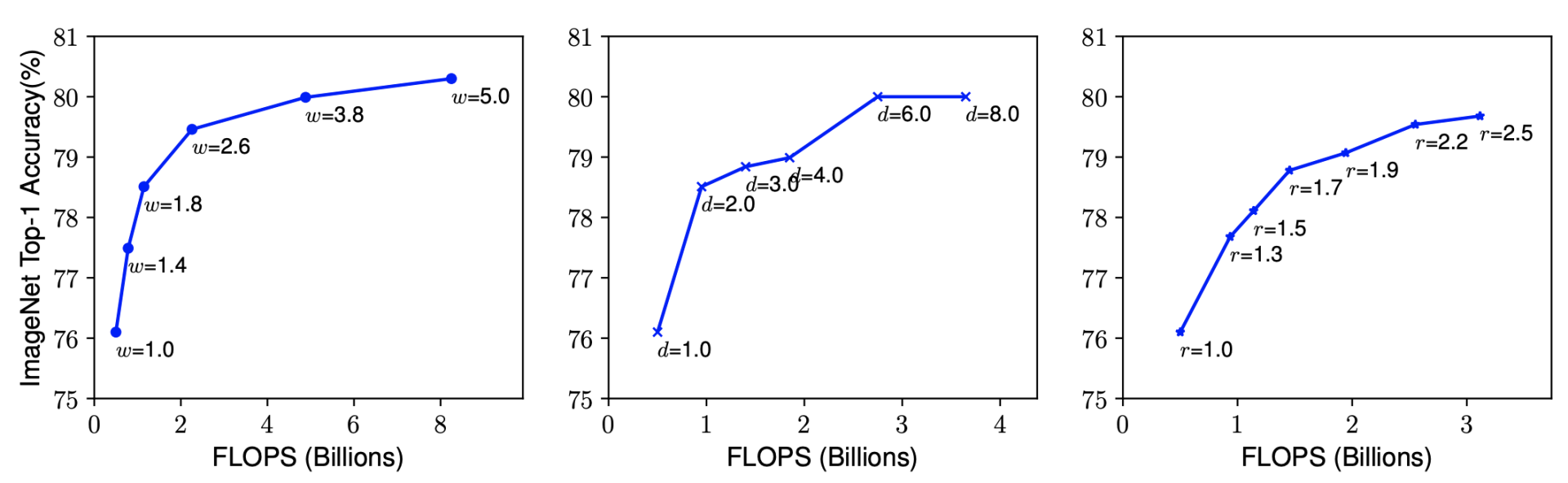
然后,作者做了第二个实验,尝试在不同的r(分辨率),d(深度)组合下变动w(宽度),得到下图:

结论是,得到更高的精度以及效率的关键是平衡网络宽度,网络深度,图像分辨率三个维度的缩放倍率(d,r,w)
因此,作者提出了混合维度放大法,该方法使用一个ϕ(混合稀疏)来决定三个维度的放大倍率
- 深度depth:
- 宽度width:
- 分辨率resolution:
第一步,固定ϕ为1,也就是计算量为2倍,使用网格搜索,得到了最佳的组合,也就是α=1.2,β=1.1,γ=1.15
第二步,固定α=1.2,β=1.1,γ=1.15,使用不同的混合稀疏ϕ,得到了B1~B7
整体评估效果如下图所示:
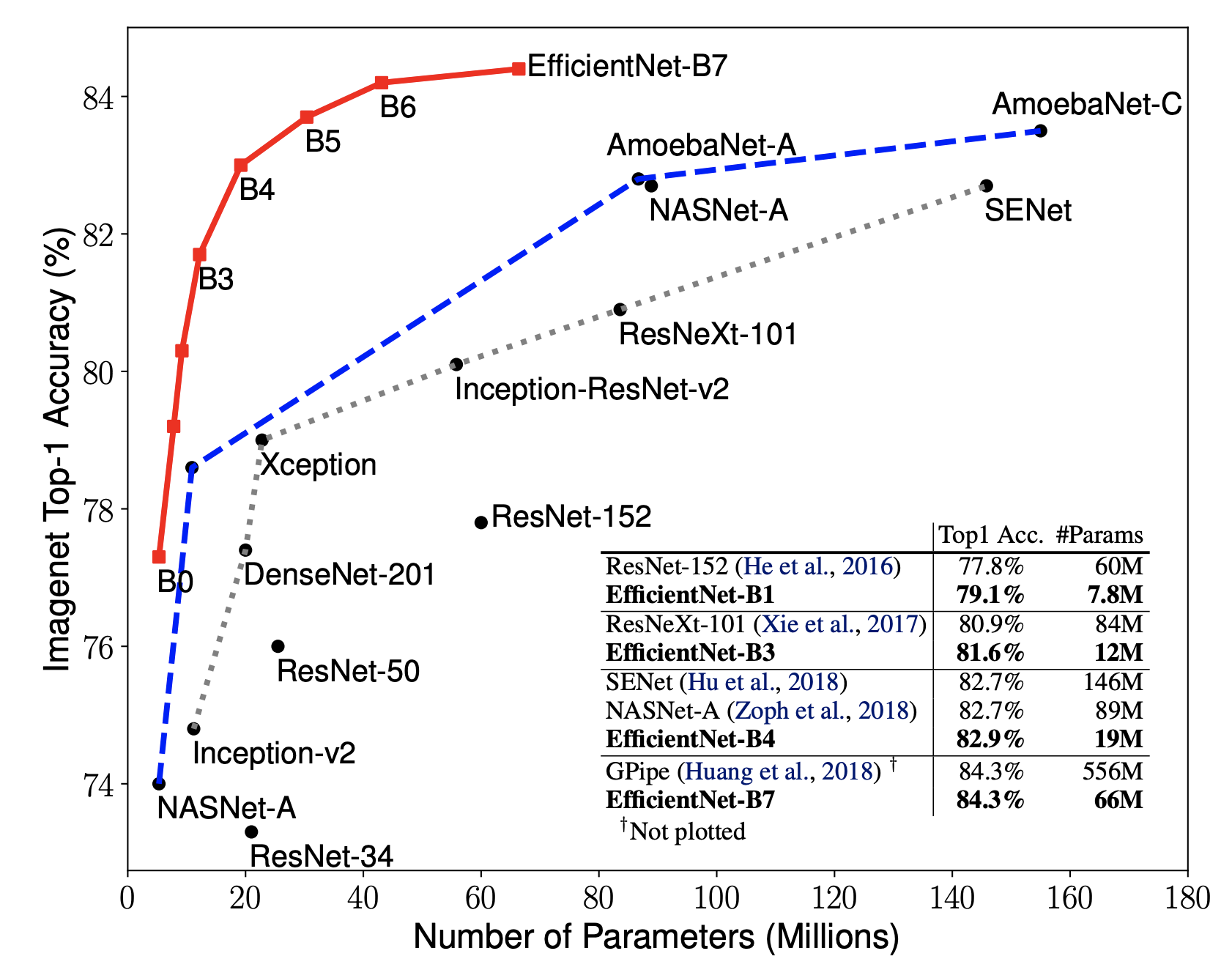
从评估结果上可以看到,EfficientNet的各个版本均超过了之前的一些经典卷积神经网络
EfficientNet v2也已经被提出来了,这里以EfficientNet为例
我们借助github,它里面有训练ImageNet的demo(demo/imagenet/main.py),接下来我们一起看看它的核心代码,然后精简一下代码,把它运行起来
相关参数(可以使用argparsem模块),如下:
