卷积
在使用卷积之前,人们尝试了很多人工神经网络来处理图像问题,但是人工神经网络的参数量非常大,从而导致非常难训练,所以计算机视觉的研究一直停滞不前,难以突破
直到卷积神经网络的出现,它的两个优秀特点:稀疏连接与平移不变性,这让计算机视觉的研究取得了长足的进步
什么是稀疏连接与平移不变性呢?简单来说,就是稀疏连接可以让学习的参数变得很少,而平移不变性则不关心物体出现在图像中什么位置
最简单的情况
我们先看最简单的情况,输入是一个4×4的特征图,卷积核的大小为2×2
卷积核是什么呢?其实就是我们卷积层要学习到的参数,就像下图中红色的示例,下图中的卷积核是最简单的情况,只有一个通道
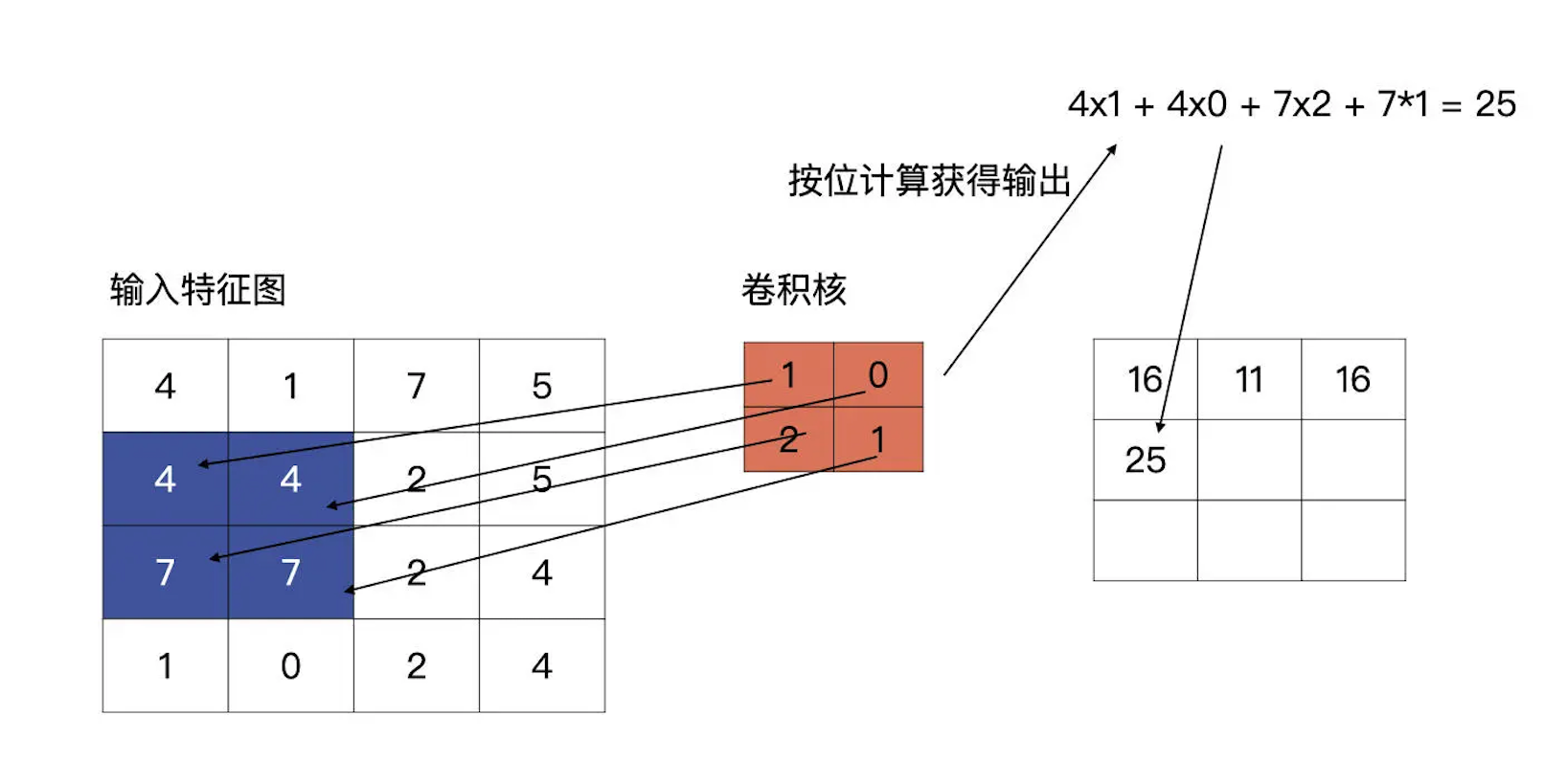
卷积上下左右滑动的长度,我们称为步长,用stride表示。上述例子中的步长就是1,根据问题的不同,会取不同的步长,但通常来说步长为1或2
标准的卷积
输入的特征有m个通道,宽为w,高为h;输出有n个特征图,宽为w',高为h';卷积核的大小为k×k
在刚才的例子中m、n、k、w、h、w'、h'的值分别为1、1、2、4、4、3、3。而现在,我们需要把一个输入为(m,h,w)的输入特征图经过卷积计算,生成一个输出为(n,h',w')的特征图
输出特征图的通道数由卷积核的个数决定的,所以说卷积核的个数为n。根据卷积计算的定义,输入特征图有m个通道,所以每个卷积核里要也要有m个通道。所以,我们的需要n个卷积核,每个卷积核的大小为(m,k,k)
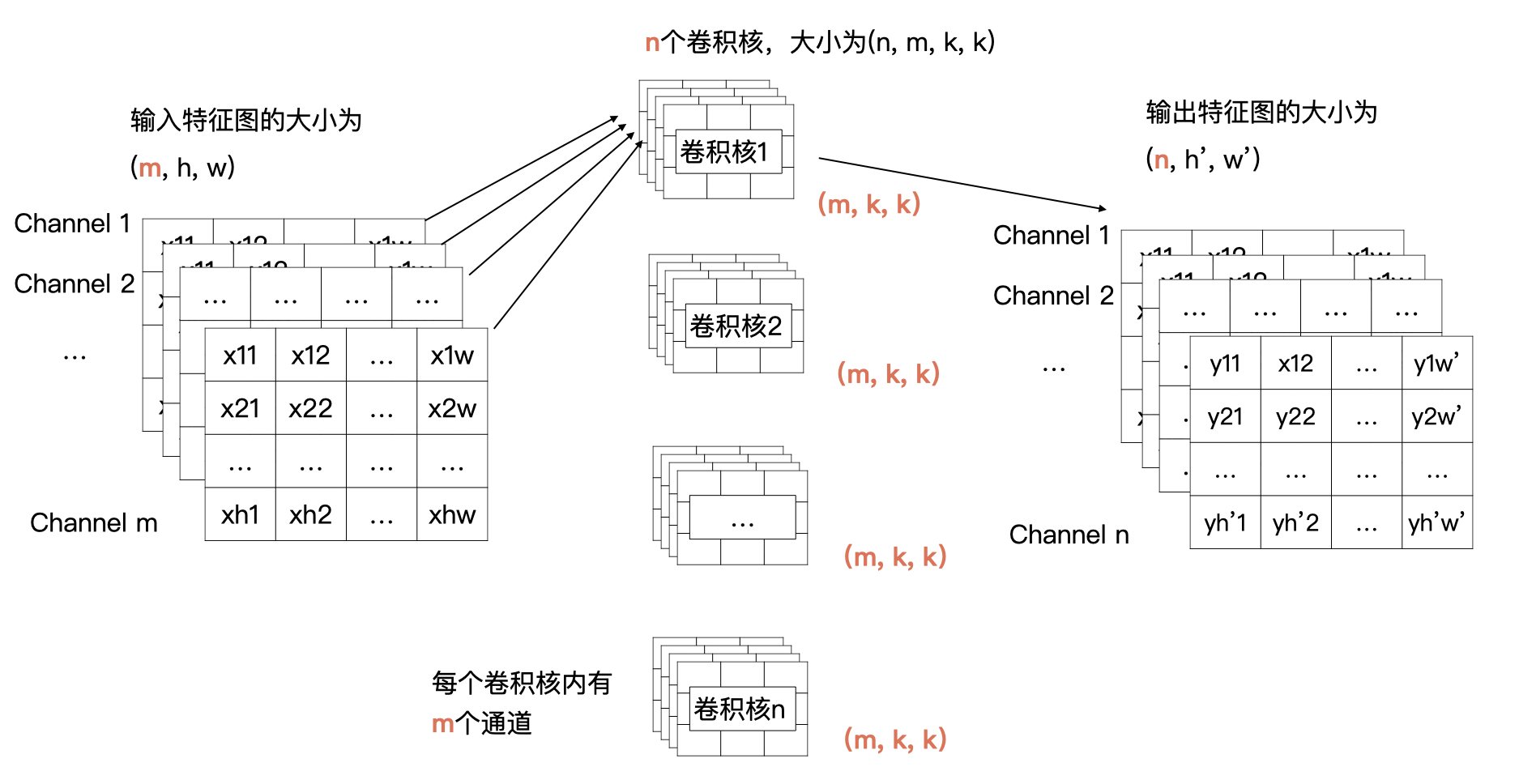
结合上面的图解可以看到,卷积核1与全部输入特征进行卷积计算,就获得了输出特征图中第1个通道的数据,卷积核2与全部输入特征图进行计算获得输出特征图中第2个通道的数据。以此类推,最终就能计算n个输出特征图
输入特征的每一个通道与卷积核中对应通道的数据按我们之前讲过的方式进行卷积计算,也就是输入特征图中第i个特征图与卷积核中的第i个通道的数据进行卷积
这样计算后会生成m个特征图,然后将这m个特征图按对应位置求和即可,求和后m个特征图合并为输出特征中一个通道的特征图
我们可以用后面的公式表示当输入有多个通道时,每个卷积核是如何与输入进行计算的
- :表示计算第i个输出特征图,i的取值为1到n
- :表示1个卷积核里的第k个通道的数据
- :表示输入特征图中的第k个通道的数据
- :为偏移项,我们在训练时一般都会默认加上
- :为卷积计算
为什么要加bias。就跟回归方程一样,如果不加bias的话,回归方程为y=wx不管w如何变化,回归方程都必须经过原点。如果加上bias的话,回归方程变为y=wx+b,这样就不是必须经过原点,可以变化的更加多样
Padding
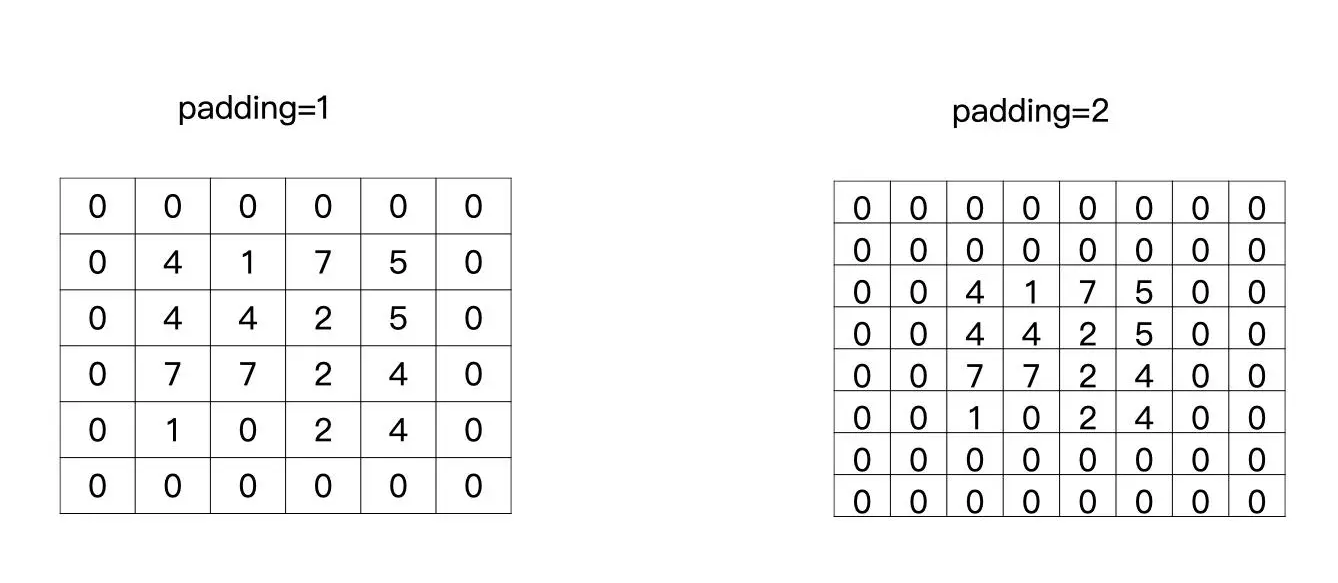
让我们回到开头的例子,可以发现,输入的尺寸是4×4,输出的尺寸是3×3。你有没有发现,输出的特征图变小了?没错,在有多层卷积层的神经网络中,特征图会越来越小
但是,有的时候我们为了让特征图变得不是那么小,可以对特征图进行补零操作。这样做主要有两个目的:
- 有的时候需要输入与输出的特征图保持一样的大小
- 让输入的特征保留更多的信息
如果不补零且步长(stride)为1的情况下,当有多层卷积层时,特征图会一点点变小。如果我们希望有更多层卷积层来提取更加丰富的信息时,就可以让特征图变小的速度稍微慢一些,这个时候就可以考虑补零
这个补零的操作就叫做padding,padding等于1就是补一圈的零,等于2就是补两圈的零,如下图所示:
PyTorch中的卷积
卷积操作定义在torch.nn(neural network)模块中,torch.nn模块为我们提供了很多构建网络的基础层与方法
在torch.nn模块中,关于卷积操作有nn.Conv1d(一维)、nn.Conv2d(二维)与nn.Conv3d(三维)三个类
nn.Conv2d用的最多,相关参数描述如下
import torch
'''
二维卷积
in_channels:输入特征图的通道数,数据类型为int,在标准卷积的讲解中in_channels为m
out_channels:输出特征图的通道数,数据类型为int,在标准卷积的讲解中out_channels为n
kernel_size:卷积核的大小,数据类型为int或tuple,需要注意的是只给定卷积核的高与宽即可,在标准卷积的讲解中kernel_size为k
stride:滑动的步长,数据类型为int或tuple,默认是1,在前面的例子中步长都为1
padding:补零的方式,数据类型为int或tuple或str,str只有2个选项:'valid'或'same',padding为str时stride必须为1
'valid'就是没有padding操作;'same'则是让输出的特征图与输入的特征图获得相同的大小
'same':当滑动到特征图最右/下侧时,发现输出的特征图的宽与输入的特征图的宽不一致,它会自动补零,直到输出特征图的宽与输入特征图的宽一致为止
bias:是否使用偏移项
groups:将输入特征图分组进行计算。深度可分离卷积中,该参数等于输入特征图数
dilation:空洞率
'''
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True,
padding_mode='zeros', device=None, dtype=None)
二维卷积示例
import torch
import torch.nn as nn
input_feat = torch.tensor([[4, 1, 7, 5], [4, 4, 2, 5], [7, 7, 2, 4], [1, 0, 2, 4]], dtype=torch.float32)
conv2d = nn.Conv2d(1, 1, (2, 2), stride=1, padding='same', bias=False)
# 卷积核默认情况下是随机初始化的。一般情况下,我们不会人工强行干预卷积核的初始化,现在为了验证,我们人工对卷积核的参数进行初始化
# 卷积核要有四个维度(输入通道数,输出通道数,高,宽)
kernels = torch.tensor([[[[1, 0], [2, 1]]]], dtype=torch.float32)
conv2d.weight = nn.Parameter(kernels, requires_grad=False)
# 输入tensor的维度信息是(batch_size,通道数,高,宽)
output = conv2d(torch.reshape(input_feat, (1, 1, 4, 4)))
print(output)
深度可分离卷积(Depthwise Separable Convolution)
虽然标准卷积大部分场景已经够用了,但是人们还是基于标准卷积,提出了一些其它的卷积方式,这些卷积方式在应对不同问题时能够发挥不同的作用
- 深度可分离卷积:用于轻量化模型
- 空洞卷积:常用于图像分割
- 转置卷积:常用于图像分割
- 残差卷积块:为了提高网络精度的一种组合
- Inception模块:为了提高网络精度的一种组合
- SE块:为了提高网络精度的一种组合
PyTorch中conv2d中的groups、dilation参数,分别对应着两种不同的卷积,分别是深度可分离卷积和空洞卷积
我们先看看依托groups参数实现的深度可分离卷积
随着深度学习技术的不断发展,许多很深、很宽的网络模型被提出,例如,VGG、ResNet、SENet、DenseNet等,这些网络利用其复杂的结构,可以更加精确地提取出有用的信息
同时也伴随着硬件算力的不断增强,可以将这些复杂的模型直接部署在服务器端,在工业中可以落地的项目中都取得了非常优秀的效果
但这些模型具有一个通病,就是速度较慢、参数量大,这两个问题使得这些模型无法被直接部署到移动终端上。而移动端的各种应用无疑是当今最火热的一个市场,这种情况下这些深而宽的复杂网络模型就不适用了
因此,很多研究将目光投入到寻求更加轻量化的模型当中,这些轻量化模型的要求是速度快、体积小,精度上允许比服务器端的模型稍微降低一些
深度可分离卷积就是谷歌在MobileNet v1中提出的一种轻量化卷积
深度可分离卷积(Depthwise Separable Convolution)由Depthwise(DW)和Pointwise(PW)这两部分卷积组合而成的
DW卷积就是有m个卷积核的卷积,每个卷积核中的通道数为1,这m个卷积核分别与输入特征图对应的通道数据做卷积运算,所以DW卷积的输出是有m个通道的特征图。通常来说,DW卷积核的大小是3×3的
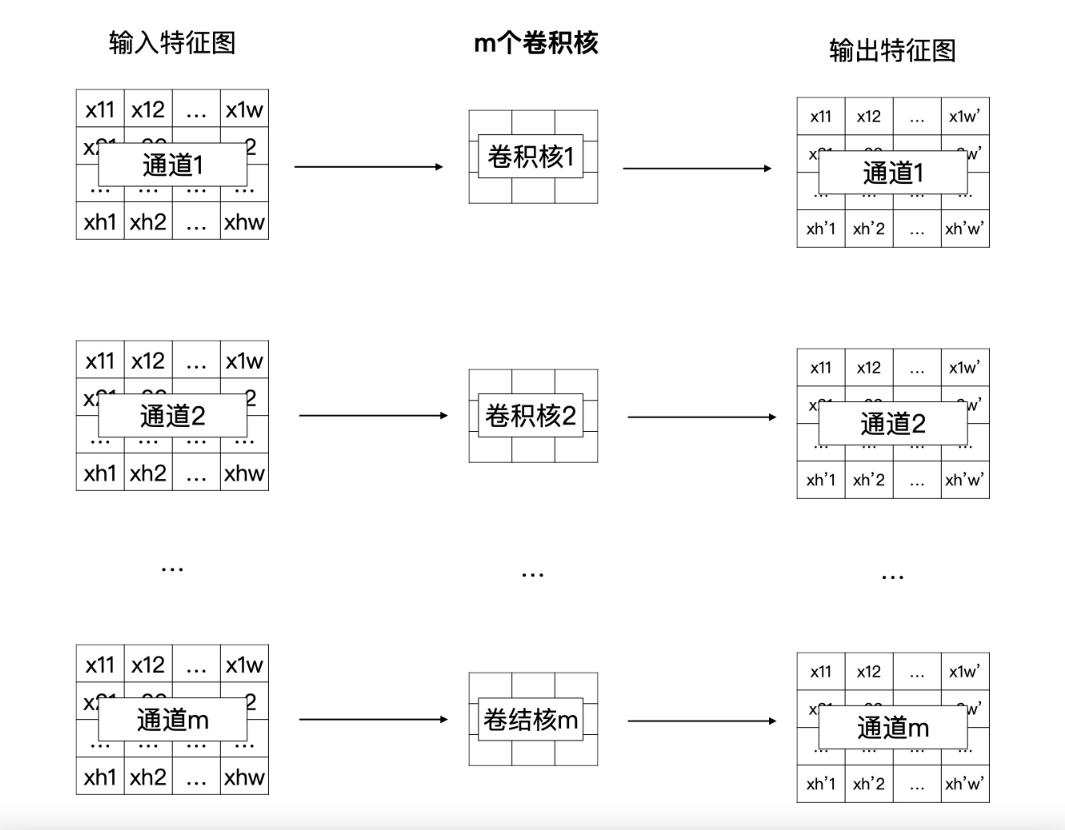
通常来说,深度可分离卷积的目标是轻量化标准卷积计算的,所以它是可以来替换标准卷积的,这也意味着原卷积计算的输出尺寸是什么样,替换后的输出尺寸也要保持一致
所以,在深度可分离卷积中,我们最终要获得一个具有n个通道的输出特征图,而刚才介绍的DW卷积显然没有达到,并且DW卷积也忽略了输入特征图通道之间的信息
所以,在DW之后我们还要加一个PW卷积。PW卷积也叫做逐点卷积。PW卷积的主要作用就是将DW输出的m个特征图结合在一起考虑,再输出一个具有n个通道的特征图
在卷积神经网络中,我们经常可以看到使用1×1的卷积,1×1的卷积主要作用就是升维与降维。所以,在DW的输出之后的PW卷积,就是n个卷积核的1×1的卷积,每个卷积核中有m个通道的卷积数据,如下图:
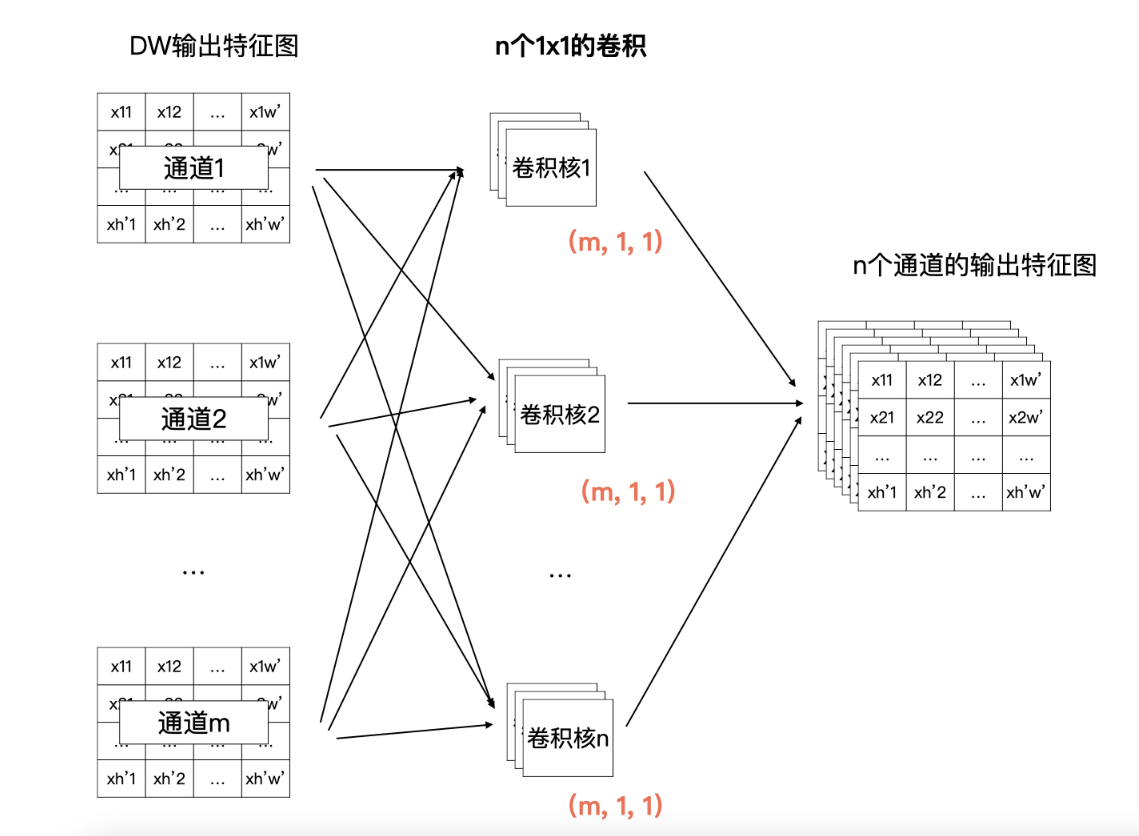
经过这样的DW与PW的组合,我们就可以获得一个与标准卷积有同样输出尺寸的轻量化卷积啦。既然是轻量化,那么我们下面就来看看,深度可分离卷积的计算量相对于标准卷积减少了多少呢?
我们的原问题是有m个通道的输入特征图,卷积核尺寸为k×k,输出特征图的尺寸为(n,h',w'),那么标准的卷积的计算量为:
k × k × m × n × h' × w'
我们是怎么得出这个结果的呢?
每个点的数值是由n个卷积核与输入特征图计算出来的,这个计算量是k × k × m × n,那输出特征图有多少个点?没错,一共有h' × w'个。所以,我们自然就得出上面的计算方式了
- k × k × m:每个卷积核在m个输入上扫一遍
- × n:有n个卷积核的话,上面的操作要重复n遍
- × h' × w':最后要把n遍中的扫描结果累加起来
如果采用深度可分离卷积,DW的计算量为:k × k × m × h' × w',而PW的计算量为:1 × 1 × m × n × h' × w'
我们不难得出标准卷积与深度可分离卷积计算量的比值为:
所以,深度可分离卷积的计算量大约为普通卷积计算量的
PyTorch中的实现
在PyTorch中实现深度可分离卷积的话,我们需要分别实现DW与PW两个卷积。我们先看看DW卷积,实现DW卷积的话,就会用到nn.Conv2d中的groups参数。groups参数的作用就是控制输入特征图与输出特征图的分组情况
当groups等于1的时候,就是标准卷积,当groups不等于1的时候,会将输入特征图分成groups个组,每个组都有自己对应的卷积核,然后分组卷积,获得的输出特征图也是有groups个分组的
需要注意的是,groups不为1的时候,groups必须能整除in_channels和out_channels
当groups等于in_channels时,就是DW卷积
- DW中,输入特征通道数与输出通道数是一样的
- 一般来讲,DW的卷积核为3×3
- DW卷积的groups参数与输出通道数是一样的
DW卷积的实现代码如下:
import torch
import torch.nn as nn
# 生成一个三通道的5x5特征图
x = torch.rand((3, 5, 5)).unsqueeze(0)
print(x.shape)
# 输出:
torch.Size([1, 3, 5, 5])
# 请注意DW中,输入特征通道数与输出通道数是一样的
in_channels_dw = x.shape[1]
out_channels_dw = x.shape[1]
# 一般来讲DW卷积的kernel size为3
kernel_size = 3
stride = 1
# DW卷积groups参数与输入通道数一样
dw = nn.Conv2d(in_channels_dw, out_channels_dw, kernel_size, stride, groups=in_channels_dw)
PW卷积的实现就是标准卷积,只不过卷积核为1x1。需要注意的是,PW卷积的groups就是默认值了
in_channels_pw = out_channels_dw
out_channels_pw = 4
kernel_size_pw = 1
pw = nn.Conv2d(in_channels_pw, out_channels_pw, kernel_size_pw, stride)
out = pw(dw(x))
print(out.shape)
空洞卷积
空洞卷积经常用于图像分割任务当中。图像分割任务的目的是要做到pixel-wise的输出,也就是说,对于图片中的每一个像素点,模型都要进行预测
对于一个图像分割模型,通常会采用多层卷积来提取特征的,随着层数的不断加深,感受野也越来越大。这里有个新名词:"感受野",这个晚点再说。我们先把空洞卷积的作用看完
但是对于图像分割模型有个问题,经过多层的卷积与pooling操作之后,特征图会变小。为了做到每个像素点都有预测输出,我们需要对较小的特征图进行上采样或反卷积,将特征图扩大到一定尺度,然后再进行预测
要知道,从一个较小的特征图恢复到一个较大的特征图,这显然会带来一定的信息损失,特别是较小的物体,这种损失是很难恢复的。那问题来了,能不能既保证有比较大的感受野,同时又不用缩小特征图呢?
空洞卷积就是解决这个问题的杀手锏,它最大的优点就是不需要缩小特征图,也可以获得更大的感受野
感受野是计算机视觉领域中经常会看到的一个概念
因为伴随着不断的pooling(池化操作,通常有最大池化和平均池化)或者卷积操作,在卷积神经网络中不同层的特征图会越来越小
这就意味着在卷积神经网络中,相对于原图来说,不同层的特征图,其计算区域是不一样的,这个区域就是感受野。感受野越大,代表着包含的信息更加全面、语义信息更加抽象,而感受野越小,则代表着包含更加细节的语义信息
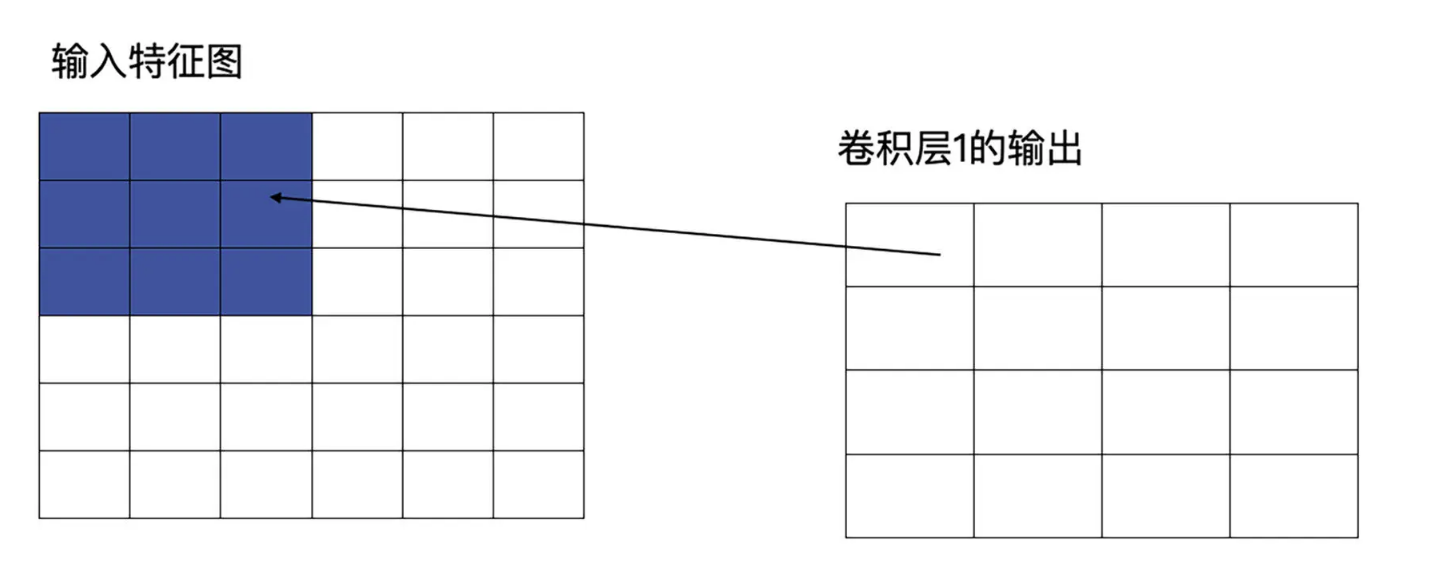
比如:原图是6×6的图像,第一层卷积层为3×3,这时它输出的感受野就是3,因为输出的特征图中每个值都是由原图中3×3个区域计算而来的
再看下图,卷积层2也为3×3的卷积,输出为2×2的特征图。这时卷积层2的感受野就会变为5(输入特征图中蓝色加橘黄色部分)
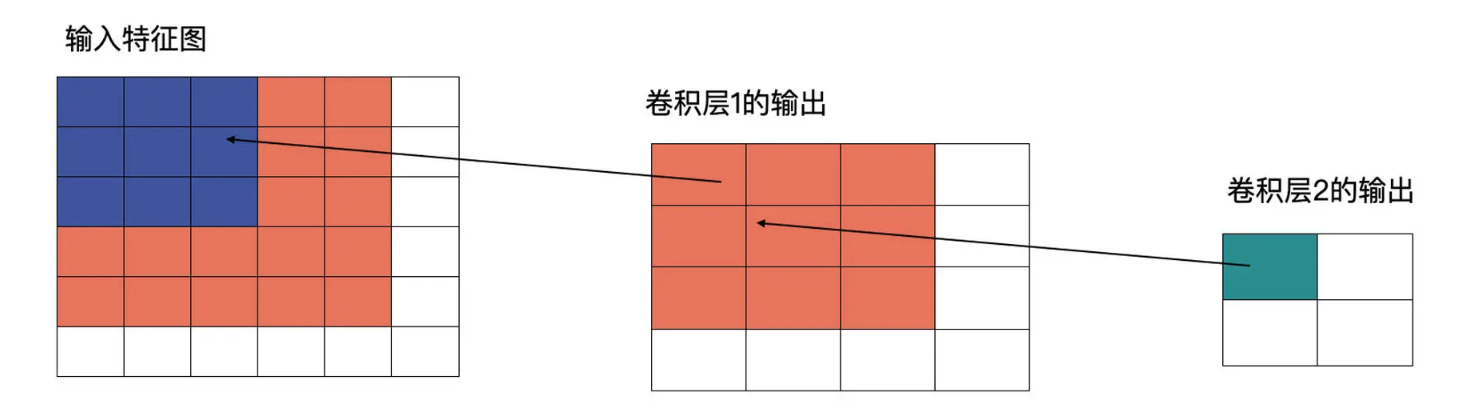
配合图解,我们就能明白感受野的含义了,我们再来看看空洞卷积具体是如何计算的
用语言来描述空洞卷积的计算方式比较抽象,我们不妨看一下它的动态示意图(这个GitHub中有各种卷积计算的动态图,非常直观,我们借助它来学习一下空洞卷积)
首先,我们先来看看标准卷积是如何计算的
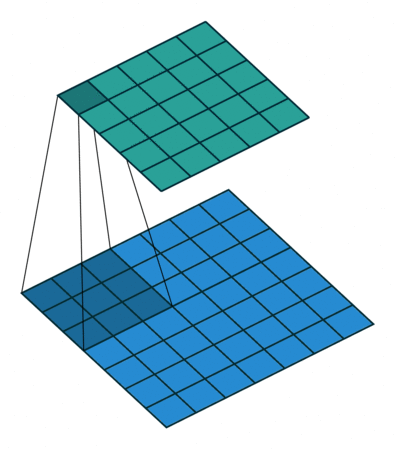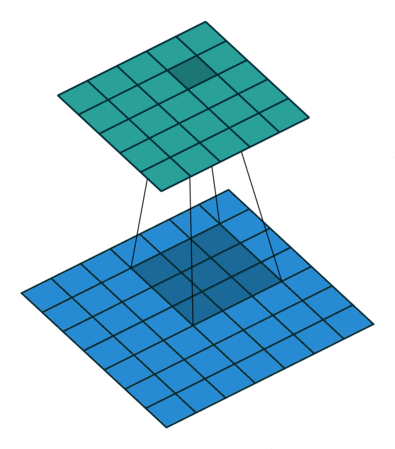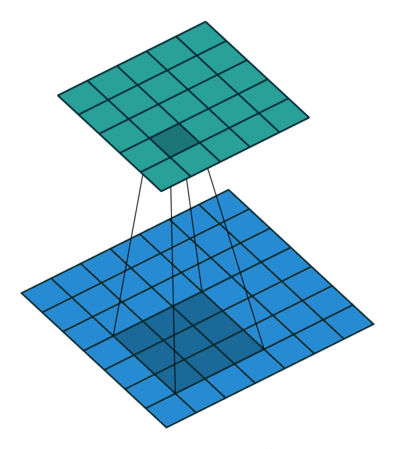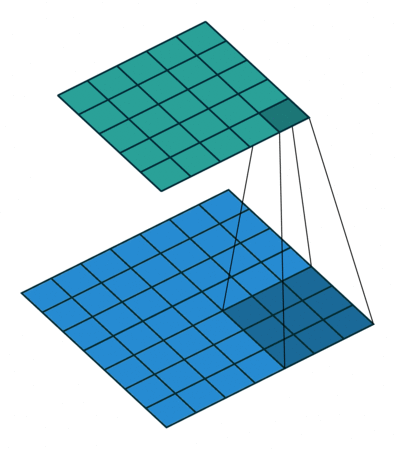
对照上图,下面的蓝图为输入特征图,滑动的阴影为卷积核,绿色的为输出特征图
然后我们再对照一下的空洞卷积示意图
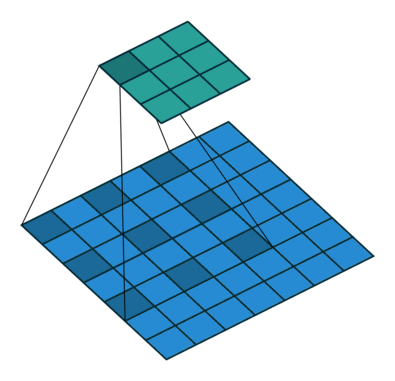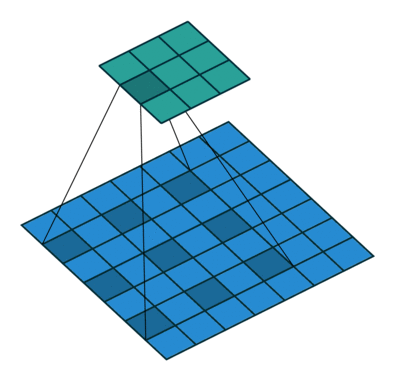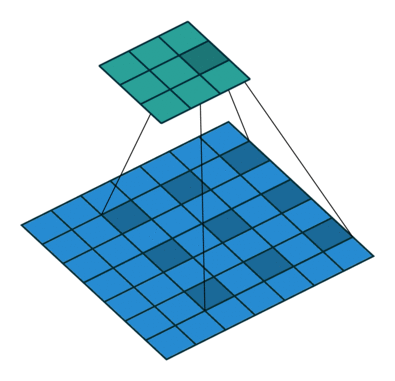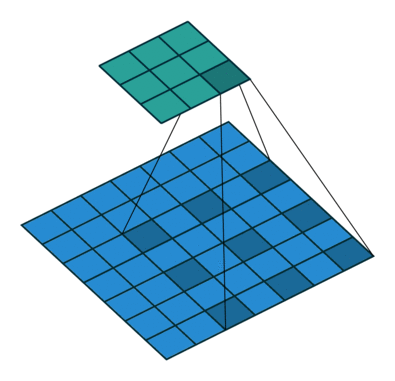
结合示意图我们会发现,计算方式与普通卷积一样,只不过是将卷积核以一定比例拆分开来。实现起来呢,就是用0来充填卷积核
这个分开的比例,我们一般称之为扩张率,就是Conv2d中的dilation参数
dilation参数默认为1,同样也是可以为int或者tuple。当为tuple时,第一位代表行的信息,第二位代表列的信息
卷积后的矩阵大小
h:height w:width p:padding k:kernel s:stride
不存在步长的场景
通常取:
当为奇数:在上下两侧填充
当为偶数:在上测填充ceil(),在下侧填充floor()
存在步长的场景
如果:
如果输入高度和宽度可以被步长整除
1×1卷积
1×1卷积核在卷积神经网络中具有多种用途。具体如下:
- 实现跨通道的信息交互与整合:1×1卷积可以改变卷积核的通道数,从而实现升维或降维操作。这意味着它可以在不改变特征图尺寸(即宽度和高度)的情况下,增加或减少网络层的深度
- 添加非线性特性:通过在网络中引入1×1卷积核,可以在保持特征图尺寸不变的情况下,增加网络的深度,从而使网络能够学习更复杂的函数
- 减少计算量和参数数量:在大型网络中,使用1×1卷积可以有效地减少计算量和参数数量,因为它可以减少或压缩特征图中的通道数,从而加快计算速度并减少内存占用
- 提高模型的表达能力:1×1卷积可以看作是一个全连接层,它在每个位置上对所有输入通道进行线性运算,然后组合这些结果。这种操作允许模型在不同的通道之间学习更加复杂的关系
总的来说,1×1卷积核是一种强大的工具,它不仅可以改变卷积神经网络中的通道维度,还可以提高模型的非线性能力和参数效率
特殊卷积核
'''
# 边缘检测
[
-1 -1 -1
-1 8 -1
-1 -1 -1
]
# 锐化,变清晰
[
0 -1 0
-1 5 -1
0 -1 0
]
# 钝化,变模糊
[
1 2 1
1/16 * 2 4 2
1 2 1
]
'''
池化
在进行边缘检测卷积的时候,对边缘数值是十分敏感的,稍稍有一点抖动,就会对影响到边缘检测的准确度
这个时候可以使用池化技术,最大池化和平均池化都行,最大池化会突出亮点,而平均池化会使得整个图片看起来很温和
不同维度的卷积
卷积使用最多的场景在图片,所以大部分是二维卷积,但是在其他维度上有些场景,也是可以使用卷积的
一维卷积:文本、语言、时间序列等
三维卷积:视频、医学图像、气象地图等
总结
通常情况,我们用标准卷积就可以了
如果说你需要轻量化你的模型,让你的模型变得更小、更快,你可以考虑将卷积层替换为深度可分离卷积
如果你在做图像分割项目的话,可以考虑将网络靠后的层替换为空洞卷积,看看效果是否能有所提高