SVM
SVM(Support Vector Machine):支持向量机。它是常见的一种分类方法,在机器学习中,SVM是有监督的学习模型
什么是有监督的学习模型呢?它指的是我们需要事先对数据打上分类标签,这样机器就知道这个数据属于哪个分类
同样无监督学习,就是数据没有被打上分类标签,这可能是因为我们不具备先验的知识,或者打标签的成本很高
所以我们需要机器代我们部分完成这个工作,比如将数据进行聚类,方便后续人工对每个类进行分析
SVM作为有监督的学习模型,通常可以帮我们模式识别、分类以及回归分析
示例1:桌子上放了红色和蓝色两种球,请用一根棍子将这两种颜色的球分开

示例2:这次难度升级,桌子上依然放着红色、蓝色两种球,但是它们的摆放不规律。那就没办法用一根棍子分开了

示例3:有没有一种方式,可以让它们自然地分开呢?这时你灵机一动,猛拍一下桌子,这些小球瞬间腾空而起,在腾起的那一刹那,出现了一个水平切面,恰好把红、蓝两种颜色的球分开
在这里,二维平面变成了三维空间。原来的曲线变成了一个平面。这个平面,我们就叫做超平面
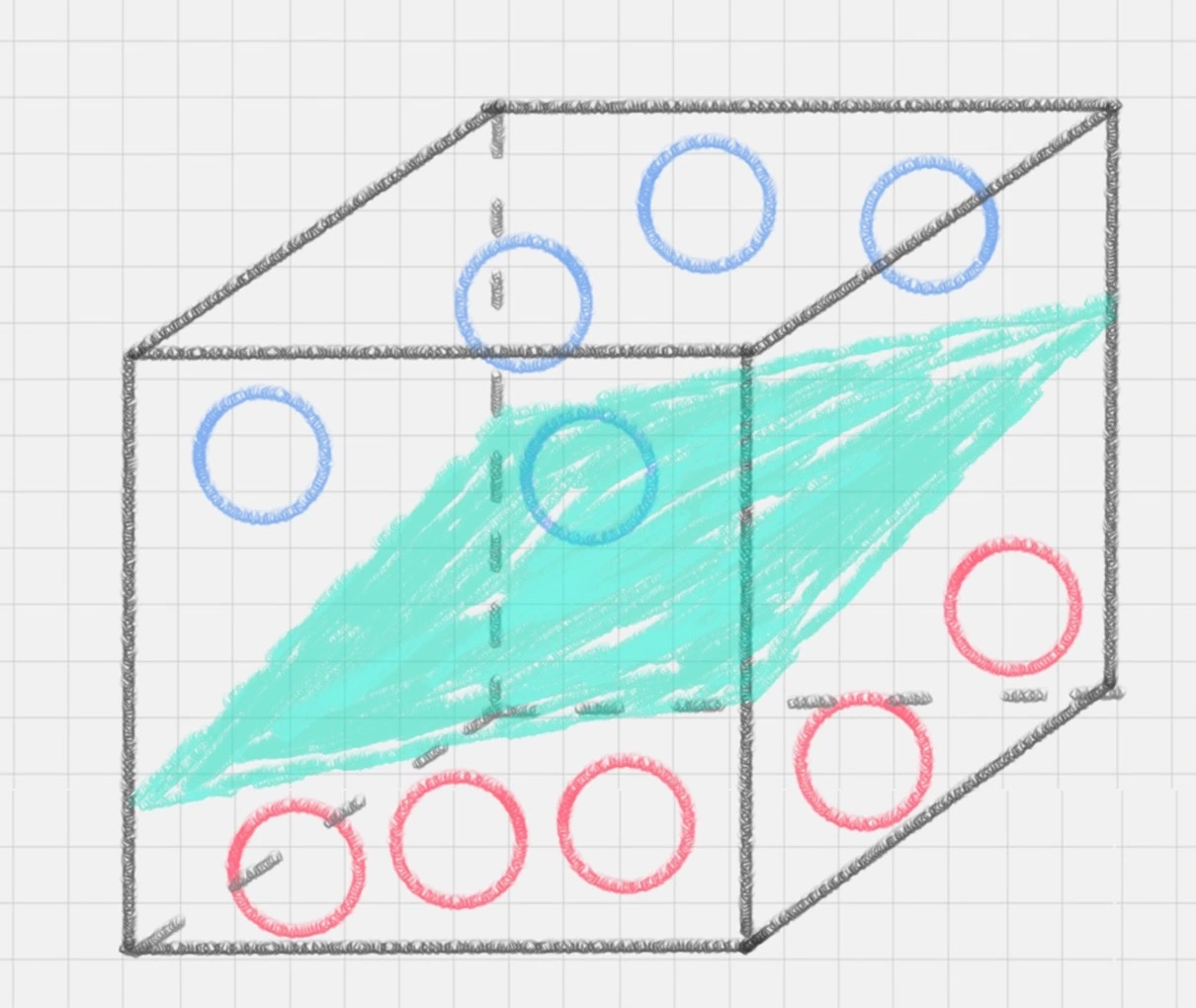
SVM的工作原理
用SVM计算的过程就是帮我们找到那个超平面的过程,这个超平面就是我们的SVM分类器
示例1其实我们可以有多种直线的划分,比如下图所示的直线A、直线B和直线C,究竟哪种才是更好的划分呢?
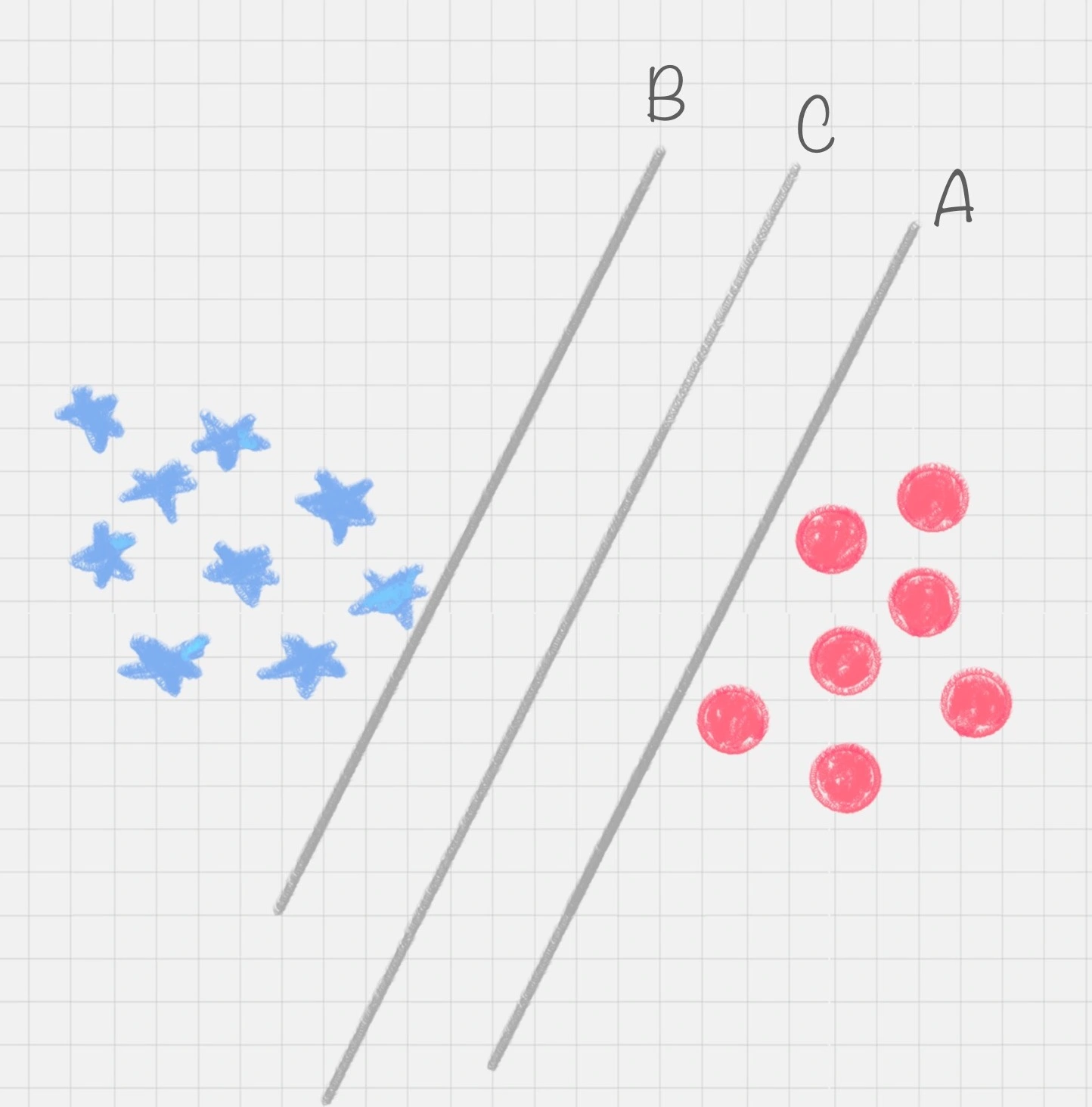
很明显图中的直线B更靠近蓝色球,但是在真实环境下,球再多一些的话,蓝色球可能就被划分到了直线B的右侧,被认为是红色球
同样直线A更靠近红色球,在真实环境下,如果红色球再多一些,也可能会被误认为是蓝色球
所以相比于直线A和直线B,直线C的划分更优,因为它的鲁棒性更强
鲁棒是Robust的音译,也就是健壮和强壮的意思。它是在异常和危险情况下系统生存的关键
分类间隔
那怎样才能寻找到直线C这个更优的答案呢?这里,我们引入一个SVM特有的概念:分类间隔
实际上,我们的分类环境不是在二维平面中的,而是在多维空间中,这样直线C就变成了决策面C
在保证决策面不变,且分类不产生错误的情况下,我们可以移动决策面C,直到产生两个极限的位置
极限的位置是指,如果越过了这个位置,就会产生分类错误。这样的话,两个极限位置A和B之间的分界线C就是最优决策面
极限位置到最优决策面C之间的距离,就是“分类间隔”,英文叫做margin
如果我们转动这个最优决策面,你会发现可能存在多个最优决策面,它们都能把数据集正确分开,这些最优决策面的分类间隔可能是不同的,而那个拥有“最大间隔”(max margin)的决策面就是SVM要找的最优解
点到超平面的距离公式
在上面这个例子中,如果我们把红蓝两种颜色的球放到一个三维空间里,决策面就变成了一个平面
这里我们可以用线性函数来表示,如果在一维空间里就表示一个点,在二维空间里表示一条直线,在三维空间中代表一个平面
当然空间维数还可以更多,这样我们给这个线性函数起个名称叫做“超平面”。超平面的数学表达可以写成
,其中
在这个公式里,w、x是n维空间里的向量,其中x是函数变量;w是法向量。法向量这里指的是垂直于平面的直线所表示的向量,它决定了超平面的方向
SVM就是帮我们找到一个超平面,这个超平面能将不同的样本划分开,同时使得样本集中的点到这个分类超平面的最小距离(即分类间隔)最大化
在这个过程中,支持向量就是离分类超平面最近的样本点,实际上如果确定了支持向量也就确定了这个超平面
所以支持向量决定了分类间隔到底是多少,而在最大间隔以外的样本点,其实对分类都没有意义
所以说,SVM就是求解最大分类间隔的过程,我们还需要对分类间隔的大小进行定义
我们定义某类样本集到超平面的距离是这个样本集合内的样本到超平面的最短距离。我们用di代表点xi到超平面wxi + b = 0的欧氏距离
因此我们要求di的最小值,用它来代表这个样本到超平面的最短距离。di可以用公式计算得出
其中||w||为超平面的范数,di的公式可以用解析几何知识进行推导
最大间隔的优化模型
我们的目标就是找出所有分类间隔中最大的那个值对应的超平面。在数学上,这是一个凸优化问题(凸优化就是关于求凸集中的凸函数最小化的问题)
通过凸优化问题,最后可以求出最优的w和b,也就是我们想要找的最优超平面
中间求解的过程会用到拉格朗日乘子,和KKT(Karush-Kuhn-Tucker)条件
硬间隔、软间隔和非线性SVM
假如数据是完全的线性可分的,那么学习到的模型可以称为硬间隔支持向量机
换个说法,硬间隔指的就是完全分类准确,不能存在分类错误的情况。软间隔,就是允许一定量的样本分类错误
我们知道,实际工作中的数据没有那么“干净”,或多或少都会存在一些噪点。所以线性可分是个理想情况。这时,我们需要使用到软间隔SVM(近似线性可分),比如下面这种情况
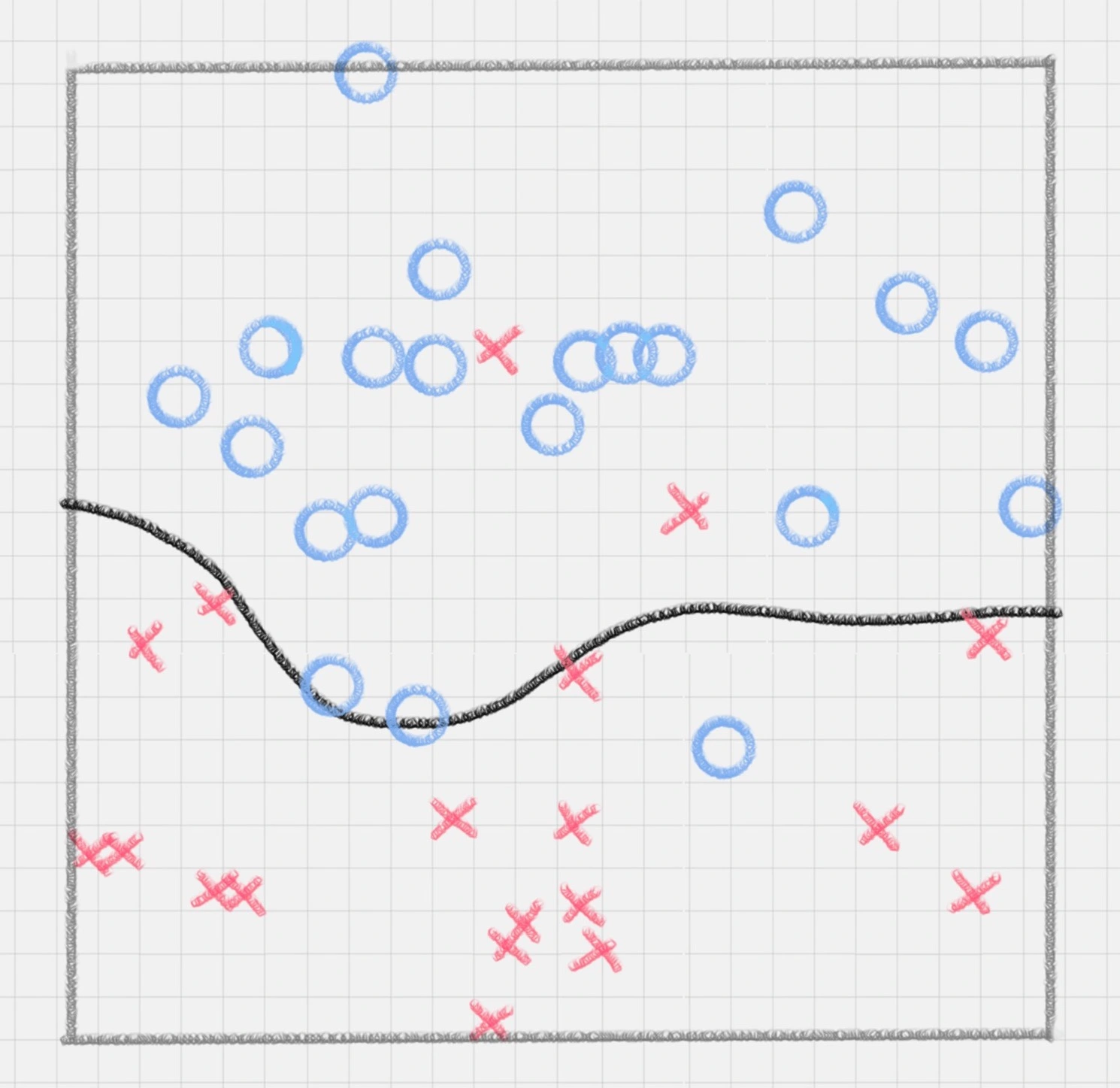
另外还存在一种情况,就是非线性支持向量机
比如下面的样本集就是个非线性的数据。图中的两类数据,分别分布为两个圆圈的形状
那么这种情况下,不论是多高级的分类器,只要映射函数是线性的,就没法处理,SVM也处理不了
这时,我们需要引入一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在新的空间中线性可分
这样我们就可以使用原来的推导来进行计算,只是所有的推导是在新的空间,而不是在原来的空间中进行

所以在非线性SVM中,核函数的选择就是影响SVM最大的变量
最常用的核函数有线性核、多项式核、高斯核、拉普拉斯核、sigmoid核,或者是这些核函数的组合
这些函数的区别在于映射方式的不同。通过这些核函数,我们就可以把样本空间投射到新的高维空间中
当然软间隔和核函数的提出,都是为了方便我们对上面超平面公式中的w和b进行求解,从而得到最大分类间隔的超平面
用SVM如何解决多分类问题
SVM本身是一个二值分类器,最初是为二分类问题设计的,也就是回答Yes或者是No。而实际上我们要解决的问题,可能是多分类的情况,比如对文本进行分类,或者对图像进行识别
针对这种情况,我们可以将多个二分类器组合起来形成一个多分类器,常见的方法有“一对多法”和“一对一法”两种
一对多法
假设我们要把物体分成A、B、C、D四种分类,那么我们可以先把其中的一类作为分类1,其他类统一归为分类2。这样我们可以构造4种SVM,分别为以下的情况
- 样本A作为正集,B,C,D作为负集
- 样本B作为正集,A,C,D作为负集
- 样本C作为正集,A,B,D作为负集
- 样本D作为正集,A,B,C作为负集
这种方法,针对K个分类,需要训练K个分类器,分类速度较快,但训练速度较慢,因为每个分类器都需要对全部样本进行训练
而且负样本数量远大于正样本数量,会造成样本不对称的情况,而且当增加新的分类,比如第K+1类时,需要重新对分类器进行构造
一对一法
一对一法的初衷是想在训练的时候更加灵活。我们可以在任意两类样本之间构造一个SVM,这样针对K类的样本,就会有C(k,2)类分类器
比如我们想要划分A、B、C三个类,可以构造3个分类器
- 分类器1:A、B
- 分类器2:A、C
- 分类器3:B、C
当对一个未知样本进行分类时,每一个分类器都会有一个分类结果,即为1票,最终得票最多的类别就是整个未知样本的类别
这样做的好处是,如果新增一类,不需要重新训练所有的SVM,只需要训练和新增这一类样本的分类器。而且这种方式在训练单个SVM模型的时候,训练速度快
但这种方法的不足在于,分类器的个数与K的平方成正比,所以当K较大时,训练和测试的时间会比较慢
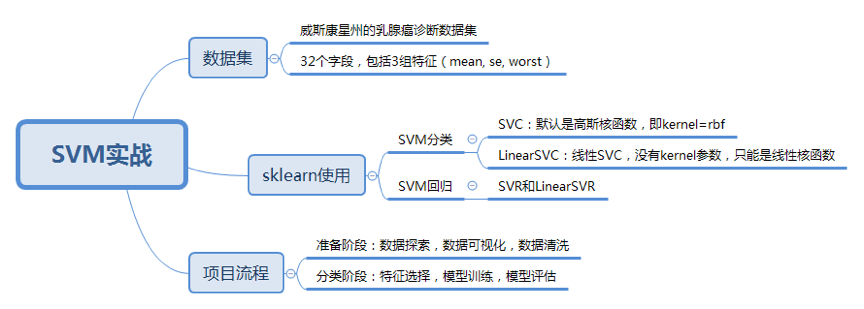
在sklearn中使用SVM
SVM既可以做回归,也可以做分类器
- 当用SVM做回归的时候,我们可以使用SVR或LinearSVR。SVR的英文是Support Vector Regression
- 当做分类器的时候,我们使用的是SVC或者LinearSVC。SVC的英文是Support Vector Classification
LinearSVC是个线性分类器,用于处理线性可分的数据,只能使用线性核函数,通过核函数将样本从原始空间映射到一个更高维的特质空间中,这样就使得样本在新的空间中线性可分
如果是针对非线性的数据,需要用到SVC。在SVC中,我们既可以使用到线性核函数(进行线性划分),也能使用高维的核函数(进行非线性划分)
from sklearn import svm
model = svm.SVC(kernel='rbf', C=1.0, gamma='auto')
# 征值矩阵train_X和分类标识train_y
model.fit(train_X,train_y)
# 预测测试样本的特征矩阵
prediction=model.predict(test_X)
kernel代表核函数的选择,它有四种选择,只不过默认是rbf,即高斯核函数
- linear:线性核函数
- poly:多项式核函数
- rbf:高斯核函数(默认)
- sigmoid:sigmoid 核函数
这四种函数代表不同的映射方式,在实际工作中,如何选择这4种核函数呢?
- 线性核函数,是在数据线性可分的情况下使用的,运算速度快,效果好。不足在于它不能处理线性不可分的数据
- 多项式核函数可以将数据从低维空间映射到高维空间,但参数比较多,计算量大
- 高斯核函数同样可以将样本映射到高维空间,但相比于多项式核函数来说所需的参数比较少,通常性能不错,所以是默认使用的核函数
- sigmoid经常用在神经网络的映射中。因此当选用sigmoid核函数时,SVM实现的是多层神经网络
参数C代表目标函数的惩罚系数,惩罚系数指的是分错样本时的惩罚程度,默认情况下为1.0
当C越大的时候,分类器的准确性越高,但同样容错率会越低,泛化能力会变差。相反,C越小,泛化能力越强,但是准确性会降低
参数gamma代表核函数的系数,默认为样本特征数的倒数,即gamma = 1 / n_features
同样我们也可以创建线性SVM分类器,在LinearSVC中没有kernel这个参数,限制我们只能使用线性核函数。由于LinearSVC对线性分类做了优化,对于数据量大的线性可分问题,使用LinearSVC的效率要高于SVC
from sklearn import svm
model = svm.LinearSVC()
model.fit(train_X,train_y)
model.predict(test_X)
如何用SVM进行乳腺癌检测
数据表一共包括了32个字段,代表的含义如下
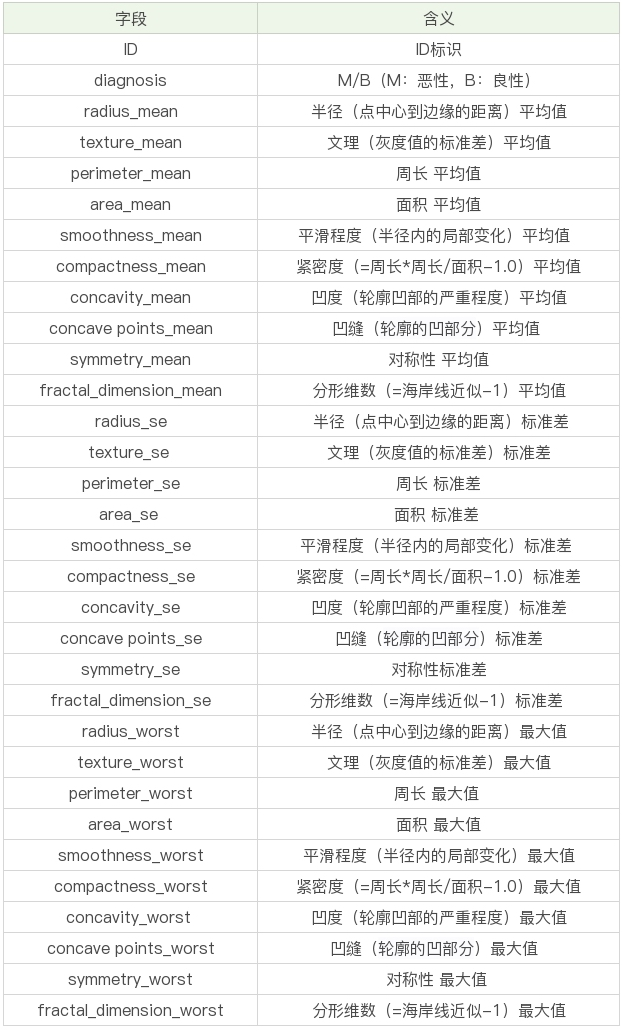
表格中mean代表平均值,se代表标准差,worst代表最大值(3个最大值的平均值)
每张图像都计算了相应的特征,得出了这30个特征值(不包括ID字段和分类标识结果字段diagnosis)
实际上是10个特征值(radius、texture、perimeter、area、smoothness、compactness、concavity、concavepoints、symmetry和fractal_dimension_mean)的3个维度,平均、标准差和最大值
这些特征值都保留了4位数字。字段中没有缺失的值。在569个患者中,一共有357个是良性,212个是恶性
我们的目标是生成一个乳腺癌诊断的SVM分类器,并计算这个分类器的准确率
首先我们需要加载数据源
在准备阶段,需要对加载的数据源进行探索,查看样本特征和特征值,这个过程你也可以使用数据可视化,它可以方便我们对数据及数据之间的关系进一步加深了解
然后按照“完全合一”的准则来评估数据的质量,如果数据质量不高就需要做数据清洗。数据清洗之后,你可以做特征选择,方便后续的模型训练
在分类阶段,选择核函数进行训练,如果不知道数据是否为线性,可以考虑使用SVC(kernel='rbf'),也就是高斯核函数的SVM分类器。然后对训练好的模型用测试集进行评估
按照上面的流程,我们来编写下代码,加载数据并对数据做部分的探索
import pandas as pd
# 加载数据集,你需要把数据放到目录中
data = pd.read_csv("./data.csv")
# 数据探索
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
print(data.columns)
print(data.head(5))
print(data.describe())
接下来,我们就要对数据进行清洗了
id是没有实际含义的,可以去掉。diagnosis字段的取值为B或者M,我们可以用0和1来替代
另外其余的30个字段,其实可以分成三组字段,下划线后面的mean、se和worst代表了每组字段不同的度量方式,分别是平均值、标准差和最大值
# 将特征字段分成3组
features_mean = list(data.columns[2:12])
features_se = list(data.columns[12:22])
features_worst = list(data.columns[22:32])
# 数据清洗
# ID列没有用,删除该列
data.drop("id", axis=1, inplace=True)
# 将B良性替换为0,M恶性替换为1
data['diagnosis'] = data['diagnosis'].map({'M': 1, 'B': 0})
然后我们要做特征字段的筛选,首先需要观察下features_mean各变量之间的关系,这里我们可以用DataFrame的corr()函数,然后用热力图帮我们可视化呈现。同样,我们也会看整体良性、恶性肿瘤的诊断情况
# 将肿瘤诊断结果可视化
sns.countplot(data['diagnosis'], label="Count")
plt.show()
# 用热力图呈现features_mean字段之间的相关性
corr = data[features_mean].corr()
plt.figure(figsize=(14, 14))
# annot=True显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()
热力图中对角线上的为单变量自身的相关系数是1。颜色越浅代表相关性越大
所以能看出来radius_mean、perimeter_mean和area_mean相关性非常大
compactness_mean、concavity_mean、concave_points_mean这三个字段也是相关的,因此我们可以取其中的一个作为代表
那么如何进行特征选择呢?
特征选择的目的是降维,用少量的特征代表数据的特性,这样也可以增强分类器的泛化能力,避免数据过拟合
我们能看到mean、se和worst这三组特征是对同一组内容的不同度量方式,我们可以保留mean这组特征,在特征选择中忽略掉se和worst
同时我们能看到mean这组特征中,radius_mean、perimeter_mean、area_mean这三个属性相关性大,compactness_mean、daconcavity_mean、concavepoints_mean这三个属性相关性大
我们分别从这2类中选择1个属性作为代表,比如radius_mean和compactness_mean
这样我们就可以把原来的10个属性缩减为6个属性,代码如下
# 特征选择
features_remain = ['radius_mean', 'texture_mean', 'smoothness_mean', 'compactness_mean', 'symmetry_mean', 'fractal_dimension_mean']
对特征进行选择之后,我们就可以准备训练集和测试集
# 抽取30%的数据作为测试集,其余作为训练集
train, test = train_test_split(data, test_size=0.3) # in this our main data is splitted into train and test
# 抽取特征选择的数值作为训练和测试数据
train_X = train[features_remain]
train_y = train['diagnosis']
test_X = test[features_remain]
test_y = test['diagnosis']
在训练之前,我们需要对数据进行规范化,这样让数据同在同一个量级上,避免因为维度问题造成数据误差
# 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)
最后我们可以让SVM做训练和预测了
# 创建SVM分类器
model = svm.SVC()
# 用训练集做训练
model.fit(train_X, train_y)
# 用测试集做预测
prediction = model.predict(test_X)
print('准确率: ', metrics.accuracy_score(test_y, prediction))
总结
选取全部的特征(除了ID以外)作为训练数据,分类器能得到的准确度更高,为什么不选取全部呢?
如果选择全部的特征,一是运算量大,二是可能会过于拟合,造成实验中的准确率高,但是在实际工作中可能会存在偏差
用SVM预测明天股价
针对单只股票的技术指标预测明天是涨还是跌(准确率极低,切勿实战)
import pandas as pd
from sklearn import svm
import numpy as np
# 加载数据集 txf_stock_factor
data = pd.read_excel("./x.xlsx")
# 有的指标全部放进去
data = data[
['open_qfq', 'close_qfq', 'high_qfq', 'low_qfq', 'pre_close_qfq', 'macd_dif', 'change', 'pct_change',
'vol', 'amount', 'macd_dea', 'macd', 'kdj_k', 'kdj_d', 'kdj_j', 'rsi_6', 'rsi_12', 'rsi_24', 'boll_upper',
'boll_mid', 'boll_lower', 'cci']]
# 今收(前复权)> 昨收(前复权),标记为1,反之标记为0
data_up = np.array(np.where(data['close_qfq'] > data.shift(1)['close_qfq'], 1, 0))
# 创建SVM分类器
model = svm.SVC()
# 用训练集做训练
model.fit(data, data_up)
# 用测试集做预测
prediction = model.predict(data[-1:])
print(prediction)