KNN
KNN也叫 K 最近邻算法,英文是 K-Nearest Neighbor。所谓 K 近邻,就是每个样本都可以用它最接近的 K 个邻居来代表。如果一个样本,它的 K 个最接近的邻居都属于分类 A,那么这个样本也属于分类 A
假设,我们想对电影的类型进行分类,统计了电影中打斗次数、接吻次数,当然还有其他的指标也可以被统计到,如下表所示
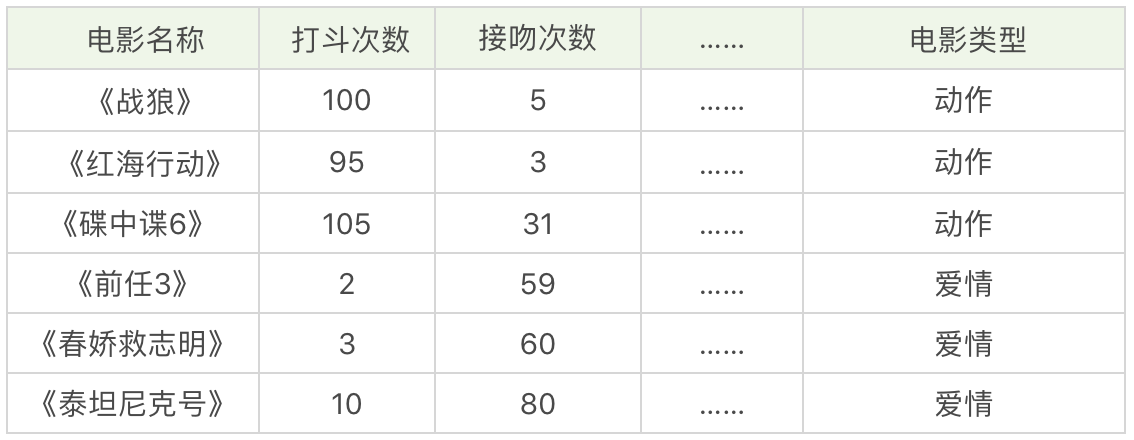
我们可以把打斗次数看成X轴,接吻次数看成Y轴,然后在二维的坐标轴上,对这几部电影进行标记,如下图所示
对于未知的电影A,坐标为(x,y),我们需要看下离电影A最近的都有哪些电影,这些电影中的大多数属于哪个分类,那么电影A就属于哪个分类
实际操作中,我们还需要确定一个K值,也就是我们要观察离电影A最近的电影有多少个

KNN的工作原理
“近朱者赤,近墨者黑”可以说是KNN的工作原理。整个计算过程分为三步:
- 计算待分类物体与其他物体之间的距离
- 统计距离最近的K个邻居
- 对于K个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类
K值如何选择
在整个KNN的分类过程,K值的选择还是很重要的。那么问题来了,K值选择多少是适合的呢?
如果K值比较小,就相当于未分类物体与它的邻居非常接近才行。这样产生的一个问题就是,如果邻居点是个噪声点,那么未分类物体的分类也会产生误差,这样KNN分类就会产生过拟合
如果K值比较大,相当于距离过远的点也会对未知物体的分类产生影响,虽然这种情况的好处是鲁棒性强,但是不足也很明显,会产生欠拟合情况,也就是没有把未分类物体真正分类出来
所以K值应该是个实践出来的结果,并不是我们事先而定的。在工程上,我们一般采用交叉验证的方式选取K值
交叉验证的思路就是,把样本集中的大部分样本作为训练集,剩余的小部分样本用于预测,来验证分类模型的准确性。所以在KNN算法中,我们一般会把K值选取在较小的范围内,同时在验证集上准确率最高的那一个最终确定作为K值
距离如何计算
在KNN算法中,还有一个重要的计算就是关于距离的度量。两个样本点之间的距离代表了这两个样本之间的相似度。距离越大,差异性越大;距离越小,相似度越大
关于距离的计算方式有下面五种方式:
- 欧氏距离
- 曼哈顿距离
- 闵可夫斯基距离
- 切比雪夫距离
- 余弦距离
其中前三种距离是KNN中最常用的距离
欧氏距离是我们最常用的距离公式,也叫做欧几里得距离。在二维空间中,两点的欧式距离就是:
同理,我们也可以求得两点在n维空间中的距离:
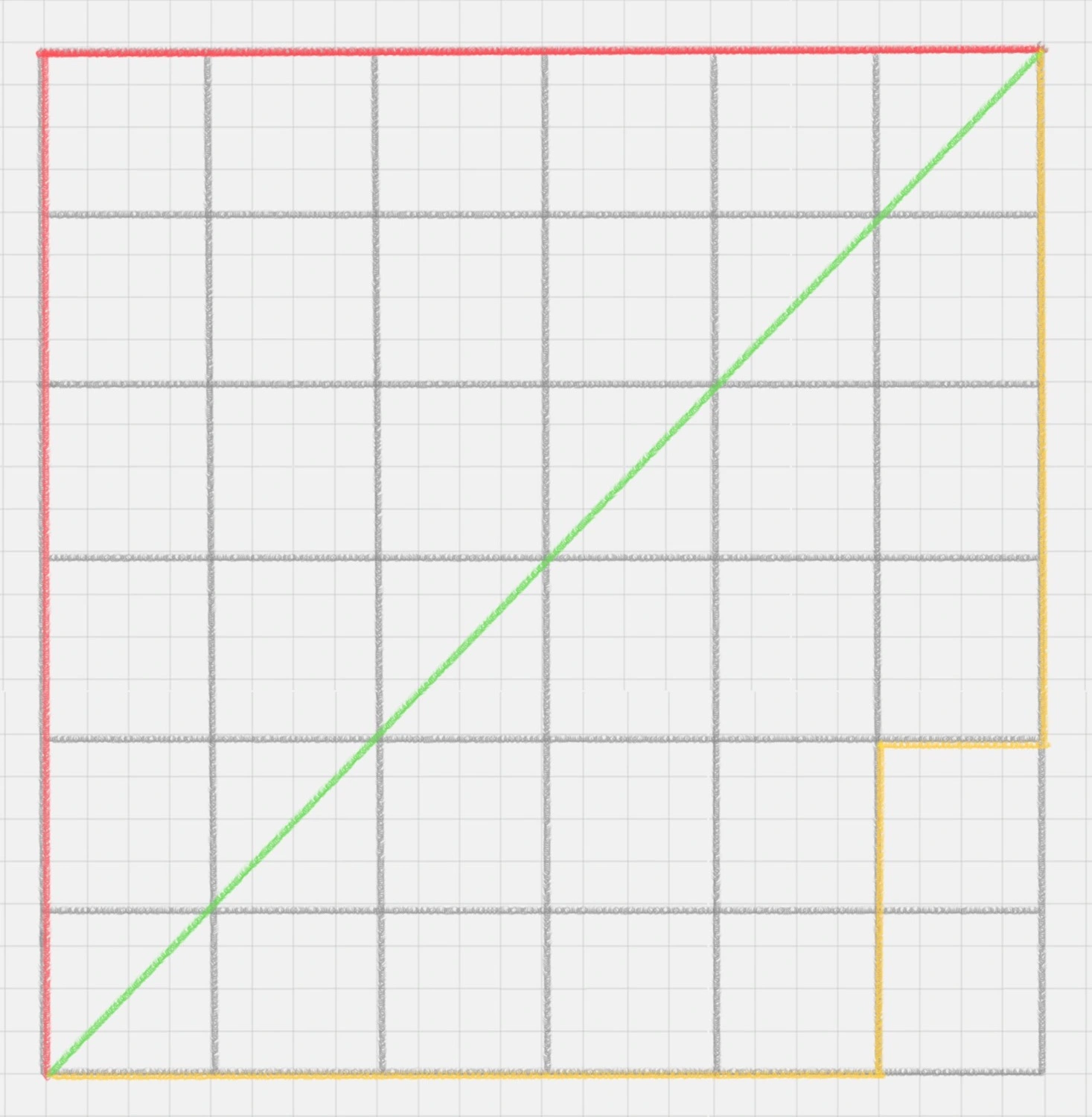
曼哈顿距离在几何空间中用的比较多。以下图为例,绿色的直线代表两点之间的欧式距离,而红色和黄色的线为两点的曼哈顿距离。所以曼哈顿距离等于两个点在坐标系上绝对轴距总和。用公式表示就是:
闵可夫斯基距离不是一个距离,而是一组距离的定义。对于n维空间中的两个点和,x和y两点之间的闵可夫斯基距离为:
其中p代表空间的维数,当p=1时,就是曼哈顿距离;当p=2时,就是欧氏距离;当p→∞时,就是切比雪夫距离
那么切比雪夫距离怎么计算呢?两个点之间的切比雪夫距离就是这两个点坐标数值差的绝对值的最大值,用数学表示就是:
余弦距离实际上计算的是两个向量的夹角,是在方向上计算两者之间的差异,对绝对数值不敏感。在兴趣相关性比较上,角度关系比距离的绝对值更重要,因此余弦距离可以用于衡量用户对内容兴趣的区分度
比如我们用搜索引擎搜索某个关键词,它还会给你推荐其他的相关搜索,这些推荐的关键词就是采用余弦距离计算得出的
KD树
KNN的计算过程是大量计算样本点之间的距离。为了减少计算距离次数,提升KNN的搜索效率,人们提出了KD树(K-Dimensional的缩写)
KD树是对数据点在K维空间中划分的一种数据结构。在KD树的构造中,每个节点都是k维数值点的二叉树。既然是二叉树,就可以采用二叉树的增删改查操作,这样就大大提升了搜索效率
在这里,我们不需要对KD树的数学原理了解太多,只需要知道它是一个二叉树的数据结构,方便存储K维空间的数据就可以了。而且在sklearn中,我们直接可以调用KD树,很方便
用KNN做回归
KNN不仅可以做分类,还可以做回归。在开头电影这个案例中,如果想要对未知电影进行类型划分,这是一个分类问题。首先看一下要分类的未知电影,离它最近的K部电影大多数属于哪个分类,这部电影就属于哪个分类
如果是一部新电影,已知它是爱情片,想要知道它的打斗次数、接吻次数可能是多少,这就是一个回归问题
对于一个新电影X,我们要预测它的某个属性值,比如打斗次数,具体特征属性和数值如下所示
此时,我们会先计算待测点(新电影X)到已知点的距离,选择距离最近的K个点。假设K=3,此时最近的3个点(电影)分别是《战狼》,《红海行动》和《碟中谍6》
那么它的打斗次数就是这3个点的该属性值的平均值,即(100+95+105)/3=100次

KNN的缺点
KNN需要计算测试点与样本点之间的距离,当数据量大的时候,计算量是非常庞大的,需要大量的存储空间和计算时间。另外如果样本分类不均衡,比如有些分类的样本非常少,那么该类别的分类准确率就会低很多
当然在实际工作中,我们需要考虑到各种可能存在的情况,比如针对某类样本少的情况,可以增加该类别的权重
同样KNN也可以用于推荐算法,虽然现在很多推荐系统的算法会使用TF-IDF、协同过滤、Apriori算法,不过针对数据量不大的情况下,采用KNN作为推荐算法也是可行的
总结

如何在sklearn中使用KNN
在Python的sklearn工具包中有KNN算法。KNN既可以做分类器,也可以做回归
# 分类
from sklearn.neighbors import KNeighborsClassifier
# 回归
from sklearn.neighbors import KNeighborsRegressor
'''
分类的常用参数介绍:
n_neighbors:即KNN中的K值,代表的是邻居的数量。K值如果比较小,会造成过拟合。如果K值比较大,无法将未知物体分类出来。一般我们使用默认值5
weights:是用来确定邻居的权重,有三种方式
1. weights=uniform,代表所有邻居的权重相同
2. weights=distance,代表权重是距离的倒数,即与距离成反比
3. 自定义函数,你可以自定义不同距离所对应的权重。大部分情况下不需要自己定义函数
algorithm:用来规定计算邻居的方法,它有四种方式
1. algorithm=auto,根据数据的情况自动选择适合的算法,默认情况选择auto
2. algorithm=kd_tree,也叫作KD树,是多维空间的数据结构,方便对关键数据进行检索,不过KD树适用于维度少的情况,一般维数不超过20,如果维数大于20之后,效率反而会下降
3. algorithm=ball_tree,也叫作球树,它和KD树一样都是多维空间的数据结果,不同于KD树,球树更适用于维度大的情况
4. algorithm=brute,也叫作暴力搜索,它和KD树不同的地方是在于采用的是线性扫描,而不是通过构造树结构进行快速检索。当训练集大的时候,效率很低
leaf_size:代表构造KD树或球树时的叶子数,默认是30,调整leaf_size会影响到树的构造和搜索速度
'''
KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30)
如何用KNN对手写数字进行识别分类
整个训练过程基本上都会包括三个阶段:
- 数据加载:我们可以直接从sklearn中加载自带的手写数字数据集
- 准备阶段:在这个阶段中,我们需要对数据集有个初步的了解,比如样本的个数、图像长什么样、识别结果是怎样的。你可以通过可视化的方式来查看图像的呈现。通过数据规范化可以让数据都在同一个数量级的维度。另外,因为训练集是图像,每幅图像是个8×8的矩阵,我们不需要对它进行特征选择,将全部的图像数据作为特征值矩阵即可
- 分类阶段:通过训练可以得到分类器,然后用测试集进行准确率的计算
首先是加载数据和对数据的探索:
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
# 加载数据
digits = load_digits()
data = digits.data
# 数据探索
print(data.shape)
# 查看第一幅图像
print(digits.images[0])
# 第一幅图像代表的数字含义
print(digits.target[0])
# 将第一幅图像显示出来
plt.gray()
plt.imshow(digits.images[0])
plt.show()
我们对原始数据集中的第一幅进行数据可视化,可以看到图像是个8×8的像素矩阵,上面这幅图像是一个“0”,从训练集的分类标注中我们也可以看到分类标注为“0”
sklearn自带的手写数字数据集一共包括了1797个样本,每幅图像都是8×8像素的矩阵。因为并没有专门的测试集,所以我们需要对数据集做划分,划分成训练集和测试集
因为KNN算法和距离定义相关,我们需要对数据进行规范化处理,采用Z-Score规范化,代码如下:
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.datasets import load_digits
# 加载数据
digits = load_digits()
data = digits.data
# 分割数据,将25%的数据作为测试集,其余作为训练集
train_x, test_x, train_y, test_y = train_test_split(data, digits.target, test_size=0.25, random_state=33)
# 采用Z-Score规范化
ss = preprocessing.StandardScaler()
train_ss_x = ss.fit_transform(train_x)
test_ss_x = ss.transform(test_x)
然后我们构造一个KNN分类器knn,把训练集的数据传入构造好的knn,并通过测试集进行结果预测,与测试集的结果进行对比,得到KNN分类器准确率,代码如下:
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
# 加载数据
digits = load_digits()
data = digits.data
# 分割数据,将25%的数据作为测试集,其余作为训练集
train_x, test_x, train_y, test_y = train_test_split(data, digits.target, test_size=0.25, random_state=33)
# 采用Z-Score规范化
ss = preprocessing.StandardScaler()
train_ss_x = ss.fit_transform(train_x)
test_ss_x = ss.transform(test_x)
# 创建KNN分类器
knn = KNeighborsClassifier()
knn.fit(train_ss_x, train_y)
predict_y = knn.predict(test_ss_x)
print("KNN准确率: %.4lf" % accuracy_score(test_y, predict_y))
完整代码,比较KNN、SVM、决策树、朴素贝叶斯算法
这里需要注意的是,我们在做多项式朴素贝叶斯分类的时候,传入的数据不能有负数。因为Z-Score会将数值规范化为一个标准的正态分布,即均值为0,方差为1,数值会包含负数。因此我们需要采用Min-Max规范化,将数据规范化到[0,1]范围内
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
# 加载数据
digits = load_digits()
data = digits.data
# 数据探索
print(data.shape)
# 查看第一幅图像
print(digits.images[0])
# 第一幅图像代表的数字含义
print(digits.target[0])
# 将第一幅图像显示出来
plt.gray()
plt.imshow(digits.images[0])
plt.show()
# 分割数据,将25%的数据作为测试集,其余作为训练集
train_x, test_x, train_y, test_y = train_test_split(data, digits.target, test_size=0.25, random_state=33)
# 采用Z-Score规范化
# fit_transform是fit和transform两个函数都执行一次。所以ss是进行了fit拟合的。只有在fit拟合之后,才能进行transform
# 在进行test的时候,我们已经在train的时候fit过了,所以直接transform即可
# 另外,如果我们没有fit,直接进行transform会报错,因为需要先fit拟合,才可以进行transform
ss = preprocessing.StandardScaler()
train_ss_x = ss.fit_transform(train_x)
test_ss_x = ss.transform(test_x)
# 创建KNN分类器
knn = KNeighborsClassifier()
knn.fit(train_ss_x, train_y)
predict_y = knn.predict(test_ss_x)
print("KNN准确率: %.4lf" % accuracy_score(test_y, predict_y))
# 创建SVM分类器
svm = SVC()
svm.fit(train_ss_x, train_y)
predict_y = svm.predict(test_ss_x)
print('SVM准确率: %0.4lf' % accuracy_score(test_y, predict_y))
# 采用Min-Max规范化
mm = preprocessing.MinMaxScaler()
train_mm_x = mm.fit_transform(train_x)
test_mm_x = mm.transform(test_x)
# 创建Naive Bayes分类器
mnb = MultinomialNB()
mnb.fit(train_mm_x, train_y)
predict_y = mnb.predict(test_mm_x)
print("多项式朴素贝叶斯准确率: %.4lf" % accuracy_score(test_y, predict_y))
# 创建CART决策树分类器
dtc = DecisionTreeClassifier()
dtc.fit(train_mm_x, train_y)
predict_y = dtc.predict(test_mm_x)
print("CART决策树准确率: %.4lf" % accuracy_score(test_y, predict_y))
实战总结
